Big Dive
Big Data and data visualization kick off bootcamp for aspiring data scientists
Big data - big unknown
When we play with data that are not so big...
Experience with big data is among top skills of a data scientist profile. However, it is not trivial to learn big data tools without necessary infrastructure and proper tutoring. While pursuing my PhD in Data science dealing with medium size data frames (< 1G), usually all can be processed on one machine. In order to get some taste of methods and challenges of Big Data, I completed Big Dive course organized by TOP-IX.
... but we want to get a taste of BIG data
 Image rights TOP-IX
During the intense 5-week course I put in practice my Python - pandas
skills and learned new libraries for distributed computing, as well
as PySpark basics. We also spent a significant amount of
time setting up the infrastructure on
amazon aws
and MongoDB. Invited keynote speakers showed us important aspects and challenges of
the data science for business and science. A bonus was an
introduction to beautiful visualization D3.js. Finally, for me the
most interesting and important part of the course was a
project realized for one of 3 companies:
IFC, Eduscopio and
TesiSquare
where in just a few days we put our best efforts to make sense of hundreds
of gigabytes of data!
Image rights TOP-IX
During the intense 5-week course I put in practice my Python - pandas
skills and learned new libraries for distributed computing, as well
as PySpark basics. We also spent a significant amount of
time setting up the infrastructure on
amazon aws
and MongoDB. Invited keynote speakers showed us important aspects and challenges of
the data science for business and science. A bonus was an
introduction to beautiful visualization D3.js. Finally, for me the
most interesting and important part of the course was a
project realized for one of 3 companies:
IFC, Eduscopio and
TesiSquare
where in just a few days we put our best efforts to make sense of hundreds
of gigabytes of data!
Introduction to the Big Dive Course
The Big Dive course is an intensive program designed to provide participants with hands-on experience in data science, with a particular focus on big data, distributed computing, and data visualization. Held over five weeks, this course serves as an essential stepping stone for those looking to transition from academia to industry or deepen their understanding of big data tools and techniques. This article will walk you through the key aspects of the course, its importance in the data science landscape, and the personal and professional growth opportunities it offers.
The Growing Importance of Big Data
In today's data-driven world, big data has become a cornerstone of decision-making processes across various industries. The ability to process and analyze large volumes of data efficiently is a top skill for any data scientist. However, working with big data comes with its own set of challenges, such as the need for specialized tools and infrastructure. The Big Dive course provides a comprehensive introduction to these challenges, helping participants understand the significance of big data and equipping them with the necessary skills to tackle it.
Learning Big Data Tools and Infrastructure
One of the key highlights of the Big Dive course is the hands-on training in big data tools and infrastructure. Participants work extensively with Python and Pandas for data manipulation and learn the basics of PySpark for distributed computing. Setting up infrastructure on platforms like AWS and MongoDB is another critical component of the course, giving participants a solid foundation in managing and processing large data sets.
Learning Big Data Tools and Infrastructure
One of the key highlights of the Big Dive course is the hands-on training in big data tools and infrastructure. Participants work extensively with Python and Pandas for data manipulation and learn the basics of PySpark for distributed computing. Setting up infrastructure on platforms like AWS and MongoDB is another critical component of the course, giving participants a solid foundation in managing and processing large data sets.
Deep Dive into Data Science Projects
 Image rights TOP-IX
The practical application of knowledge is at the heart of the Big Dive
course. Participants engage in real-world projects that simulate the
challenges faced by data scientists in the industry. For instance, one
project involved analyzing hundreds of gigabytes of data for the
International Finance Corporation (IFC). These projects not only reinforce the technical skills learned during
the course but also highlight the importance of applying data science in
solving complex business and scientific problems.
Image rights TOP-IX
The practical application of knowledge is at the heart of the Big Dive
course. Participants engage in real-world projects that simulate the
challenges faced by data scientists in the industry. For instance, one
project involved analyzing hundreds of gigabytes of data for the
International Finance Corporation (IFC). These projects not only reinforce the technical skills learned during
the course but also highlight the importance of applying data science in
solving complex business and scientific problems.
The Role of Visualization in Data Science
Data visualization is a crucial aspect of data science, allowing data scientists to present complex data in a more understandable and actionable format. The Big Dive course introduces participants to advanced data visualization techniques, with a particular focus on D3.js, a powerful JavaScript library for creating interactive graphs. The course emphasizes the importance of visualization in data science projects, helping participants understand how to effectively communicate their findings.
Interactive Graphs with D3.js
D3.js is known for its ability to create dynamic, interactive graphs that can bring data to life. However, mastering D3.js comes with a steep learning curve. Participants in the Big Dive course learn how to overcome these challenges, create effective data visualizations, and explore alternatives like RShiny for those who prefer less complex tools. Understanding the intricacies of D3.js not only enhances the visual appeal of data presentations but also improves the interpretability of the data itself.
Data Science Bootcamps: Are They Worth It?
Data science bootcamps, like the Big Dive, are becoming increasingly popular as a fast track to acquiring the skills needed in the industry. But are they worth the investment? The answer is a resounding yes. At least Big Dive course made a significant touchpoint in my career. The course offers a unique opportunity to gain practical experience, build a professional network, and explore the world of big data in depth. For those looking to accelerate their career in data science, a bootcamp like the Big Dive is an excellent starting point.
Key Skills Acquired During the Big Dive
Participants leave the Big Dive course with a wealth of new skills. These include distributed computing, which is essential for handling large datasets, and the basics of PySpark, a tool widely used in big data processing. The course also offers a refresher on machine learning and network science, with practical mini-projects that can be used as portfolio pieces. The importance of understanding the data science cycle and applying it to real-world scenarios is another critical takeaway from the course.
Challenges Faced During the Course
Learning new technologies and tools is never without its challenges. The Big Dive course participants face several hurdles, such as the steep learning curve of D3.js and the complexities of distributed computing with Dask. Additionally, handling large datasets often requires substantial computational resources, which can be a significant challenge. However, overcoming these challenges is a key part of the learning process, preparing participants for the demands of the industry.
Networking Opportunities and Professional Growth
One of the most valuable aspects of the Big Dive course is the networking opportunities it offers. Participants build connections with industry professionals, course instructors, and peers, all of whom can play a crucial role in their professional development. The course also provides resources for career development, such as a CV repository and job postings from partner companies. Leveraging these connections on platforms like LinkedIn can significantly boost one’s career in data science.
Practical aspect of the big dive data science bootcamp
The course took place in a group of 20 students, with STEM/linguistic/design background, mostly from Italy but there were also a few foreign folks like me. Our diversity helped a lot during the group project when each of us could bring different perspective and skillset.
How to apply
In order to apply, a candidate needs to send a video explaining why he or she is a good fit for the big dive as well as state level of her/his prerequisites.
Detailed content of the big dive bootcamp
If you want to read more about the content of the course you can check out Big Dive website as well as read their great posts on LinkedIn of Christian Racca, Facebook page and twitter @bigdive_eu.
Who are the participants of the data science bootcamp ?
For most of the participants and for me it was the first time with Big data. I found the possibility to face the problems and tools I don't encounter in my everyday work. The content of the course was quite densely packed and I will need some time after the course to practice new skills and read all material. Thanks to great teachers like among others Alex Comunian and Fabio Franchino classes were very interactive and easy to follow.
Who are the instructors of the data science bootcamp ?
The instructors of the Big Dive course bring a wealth of industry experience to the table. Their insights into the practical applications of data science, the importance of domain knowledge, and the latest trends in the field are invaluable. Participants benefit from their interactive teaching style and the real-world examples they provide. The course also emphasizes the importance of having a field expert guide the analysis, ensuring that the data science work is truly impactful in its application.
The Future of Data Science and Engineering
As data science and engineering continue to evolve, staying updated with the latest trends and technologies is crucial. The Big Dive course prepares participants for future challenges by introducing them to emerging fields like deep learning and artificial intelligence. Understanding these trends and how they will shape the future of data science is essential for anyone looking to stay competitive in the industry.
Personal highlights
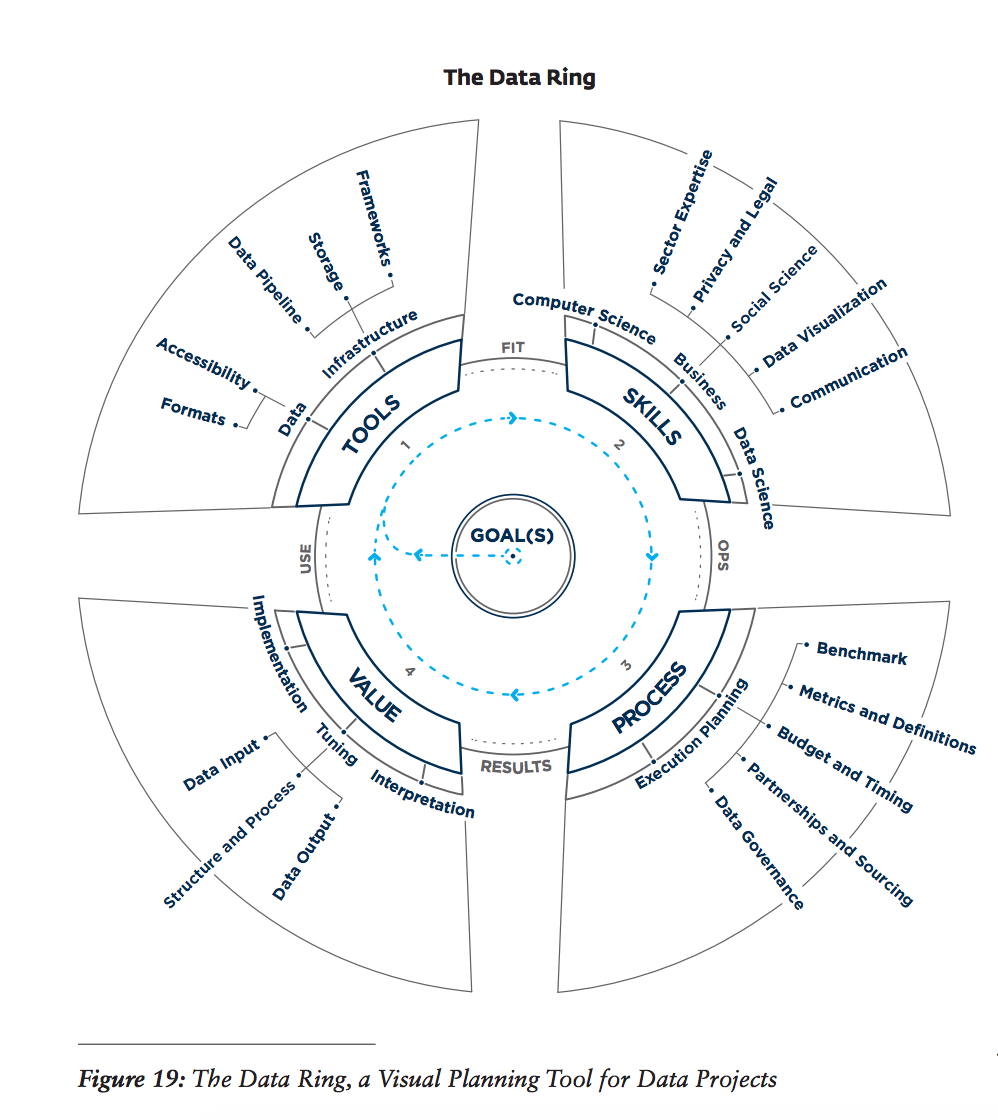

 Image rights TOP-IX
Image rights TOP-IX
Conclusion: Personal Reflections on the Big Dive
The Big Dive course offers a unique and intense learning experience that is both challenging and rewarding. Participants gain valuable skills, build professional networks, and explore the world of big data in depth. While it’s impossible to become an expert in big data in just five weeks, the course provides a strong foundation and sparks a passion for continued learning in data science. For anyone considering a career in data science, the Big Dive is an excellent starting point.
 Image rights TOP-IX
Image rights TOP-IX
Frequently Asked Questions (FAQs)
1. What is the Big Dive Course About?
The Big Dive course is a five-week intensive program designed to equip participants with practical skills in big data, distributed computing, and data visualization. It includes hands-on projects, industry insights, and networking opportunities.
2. Is a Data Science Bootcamp Worth It?
Yes, data science bootcamps like the Big Dive are worth it for those looking to gain practical experience and industry connections quickly. They offer a fast track to acquiring in-demand skills and provide a solid foundation for a career in data science.
3. How Can I Transition from Academia to Industry?
The Big Dive course is an excellent way to transition from academia to industry. It bridges the gap by offering real-world projects, networking opportunities, and exposure to industry-standard tools and practices.
4. What Tools Should I Learn for Data Science?
Key tools include Python, Pandas, PySpark, D3.js, and AWS. Understanding distributed computing, data visualization, and machine learning is also crucial for success in data science.
5. How Important is Data Visualization?
Data visualization is vital for effectively communicating complex data insights. Tools like D3.js are powerful for creating interactive and dynamic visualizations that make data more accessible and actionable.
6. Where Can I Learn More About Data Science?
Apart from bootcamps like Big Dive, you can learn more about data science through online courses, books, articles, and by joining data science communities. Continuing education is key to staying competitive in the field.
Resources and Further Reading
Continuing education is essential in the fast-paced field of data science. The Big Dive course provides participants with a list of recommended books, articles, and websites to further their learning. Joining data science communities and participating in online forums are also encouraged as ways to stay updated and connected with the industry. Resources like these ensure that participants continue to grow their skills long after the course has ended.
Useful links