AI Foundation Models
A new vision for E-commerce
“Foundation models are models that are trained on broad data and can be adapted to a wide range of downstream tasks. (…) In choosing this term, we take ‘foundation’ to designate the function of these models: a foundation is built first and it alone is fundamentally unfinished, requiring (possibly substantial) subsequent building to be useful. ‘Foundation’ also conveys the gravity of building durable, robust, and reliable bedrock through deliberate and judicious action.” — the Stanford Institute for Human-Centred AI founded the Center for Research on Foundation Models (CRFM), 2021
In the competitive realm of digital commerce, embracing technological advancements is not a luxury but a necessity for maintaining success. Among ML tools, foundation models are emerging as a formidable force. But what are foundation models, and why have they become a focal point among technologists and business leaders?
As members of ‘Cognition’, a team dedicated to computer vision at Adevinta, we are eager to share the insights we have gathered through our technology trends watch and recent attendance of the ICCV 2023 conference. This practice not only ensures our internal services remain up to date but also improves the standards experienced by our users, enhancing the services provided to customers across Adevinta’s brands.
What are foundation models ?
Foundation models are a breed of artificial intelligence (AI) models pre-trained on a vast amount of data, laying a robust groundwork for further customisation on specific tasks.
Unlike traditional machine learning models, which require from-scratch training or fine tuning for every new task, foundation models offer a substantial head start. They have already learned a good deal from the data they were initially trained on, which includes recognising patterns, objects, and in the domain of computer vision, even understanding the semantics of a scene.
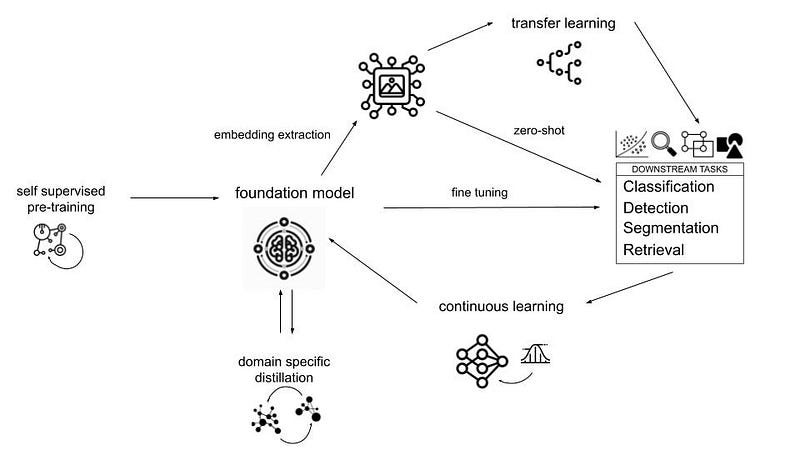
Foundation models can be leveraged in various ways, each with its own balance of resource consumption and performance enhancement. The most resource-efficient method involves extracting features from an image, “freezing” them, and then using them directly as a zero-shot retrieval, classifier or detector. This zero-shot approach requires no further learning, allowing for immediate application.
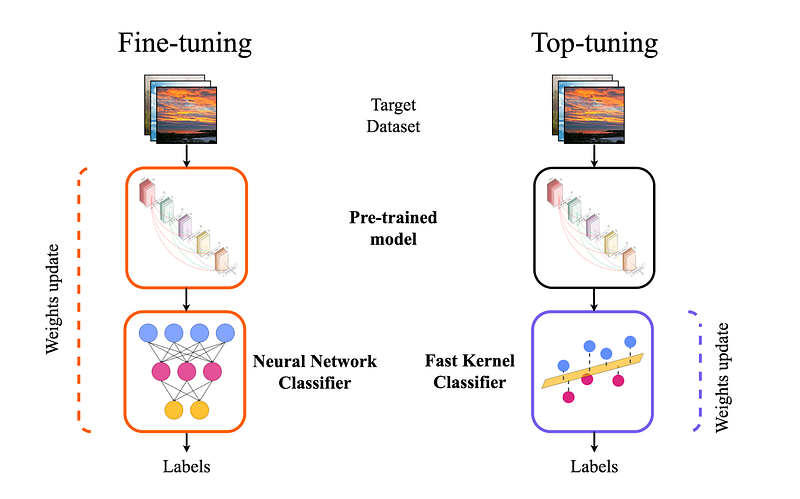
Alternatively, these embeddings can serve as inputs to other models, such as an MLP or an XGBoost classifier, through transfer learning. This strategy necessitates a minimal training dataset, yet it remains swift and cost-effective. Pastore et al reported that there can be 10x to 100x speed increase coupled with limited accuracy decrease (1–5% on average), depending on the dataset, when using a kernel classifier on top of frozen features. For a well-known CIFAR100 dataset, the authors observed 10x to 12x speed increase and −3.70% accuracy decrease. From our preliminary experiments, preparing for deploying image embedding services for Adevinta marketplaces, we noted a 5x to 10x speed increase with less than 3% accuracy drop for ImageNet1K dataset with Dinov2 frozen features compared to fine tuning a CNN backbone.
For those seeking even greater performance enhancements, fine-tuning either the last layers or the entire network is an option. This process may demand a deeper understanding of machine learning and a larger dataset for model refinement, but can lead to substantial improvements. A key challenge in this approach is maintaining the model’s generalisability and preventing it from “forgetting” previously learned datasets.
To further enrich the model with bespoke data, one can explore self-supervised learning techniques for pre-training or distillation on domain-specific data. Moreover, to ensure the model remains current with new data, continuous learning methodologies can be employed. These advanced techniques not only enhance the model’s performance, but also tailor it more closely to specific business needs and data environments.
Beyond the singular applications of foundation models lies the potential for a transformative synergy. By harnessing models trained on diverse datasets with various loss functions, we can unlock new heights of performance. This approach was masterfully demonstrated by Krishnan et al, who capitalised on images synthesised by Stable Diffusion. They adeptly trained another model (StableRep) using a contrastive loss approach and ViT backbone to achieve remarkable success in a classification benchmark. This strategy showcases the innovative fusion of generative and discriminative model capabilities, setting a new standard for adaptive and robust AI applications.
“Different foundation models understand different aspects of the world. It’s exciting that a large diffusion model, which is good at generating images, can be used to train a large vision transformer, which is good at analysing images!”
The rise of foundation models
The history of foundation models is closely tied to the rise of deep learning, particularly with the advent of large-scale models like GPT (Generative Pre-trained Transformer) by OpenAI and BERT (Bidirectional Encoder Representations from Transformers) by Google, which demonstrated the feasibility and effectiveness of pre-training models on vast datasets and then fine-tuning them for specific tasks.
As technology advanced, so did the scale and capabilities of these models, with models like GPT-3, GPT-4 and T5 showcasing unprecedented levels of generalisation and adaptability across numerous domains including natural language processing, computer vision, and even multimodal tasks combining both vision and text. The success of these models started a new era where the focus shifted from training task-specific models from scratch to developing robust, versatile foundation models. This new type of model could be fine-tuned or used in transfer-learning to excel at a broad spectrum of tasks. This shift not only catalysed significant advancements in AI research but also broadened adoption of AI across various industries, paving the way for more sophisticated and capable foundation models that continue to push the boundaries of what’s achievable with Artificial Intelligence.
Notable examples of foundation models abound in the tech landscape. For instance, DINOv2 and MAE (Masked Autoencoder) by Meta AI for image understanding. On the other hand, models like CLIP and BLIP from OpenAI have shown the potential of bridging the gap between vision and language. These models, pre-trained on diverse and voluminous datasets, encapsulate a broad spectrum of knowledge that can be adapted for more specialised tasks, making them particularly advantageous for industries with data-rich environments like e-commerce.

Here is a short description of a few of those models:
DINOv2: Developed by Meta, DINOv2 is recognised for its self-supervised learning approach in training computer vision models, achieving significant results.
The model underscores the potency of self-supervised learning in advancing computer vision capabilities.
Masked Autoencoders (MAE): MAE is a scalable self-supervised learning approach for computer vision that involves masking random patches of the input image and reconstructing the missing pixels.
Meta AI demonstrated the effectiveness of MAE pre-pre training for billion-scale pretraining, combining self-supervised (1st stage) and weakly-supervised learning (2nd stage) for improved performance.
CLIP (Contrastive Language-Image Pre-Training): Developed by OpenAI, CLIP is a groundbreaking model that bridges computer vision and natural language processing, leveraging an abundantly available source of supervision: the text paired with images found across the internet.
CLIP is the first multimodal model tackling computer vision, trained on a variety of (image, text) pairs, achieving competitive zero-shot performance on a variety of image classification datasets. It brings many of the recent developments from the realm of natural language processing into the mainstream of computer vision, including unsupervised learning, transformers, and multimodality
Segment Anything Model (SAM): Developed by Meta’s FAIR lab, SAM is a state-of-the-art image segmentation model that aims to revolutionise the field of computer vision by identifying which pixels in an image belong to which object, producing detailed object masks from input prompts.
SAM is built on foundation models that have significantly impacted natural language processing (NLP), and focuses on promptable segmentation tasks, adapting to diverse downstream segmentation problems using prompt engineering.
OneFormer/ SegFormer: A state-of-the-art multi-task image segmentation framework implemented using transformers. Parameters: 219 million. Architecture: ViT
Florence: Introduced by Microsoft, this foundation model has set new benchmarks on several leaderboards such as TextCaps Challenge 2021, nocaps, Kinetics-400/Kinetics-600 action classification, and OK-VQA Leaderboard. Florence aims to expand representations from coarse (scene) to fine (object), and from static (images) to dynamic (videos).
Stable Diffusion: A generative model utilising AI and deep learning to generate images, functioning as a diffusion model with a sequential application of denoising autoencoders.
It employs a U-Net model, specifically a Residual Neural Network (ResNet), originally developed for image segmentation in biomedicine, to denoise images and control the image generation process without retraining.
DALL-E: Developed by OpenAI, DALL-E is a generative model capable of creating images from textual descriptions, showcasing a unique blend of natural language understanding and image generation. It employs a version of the GPT-3 architecture to generate images, demonstrating the potential of transformer models in tasks beyond natural language processing
The tech titans, often bundled as GAFA (Google, Amazon, Facebook and Apple), alongside several other companies such as Hugging Face, Anthropic, AI21 Labs, Cohere, Aleph Alpha, Open AI and Salesforce have been instrumental in developing, utilising and advancing foundation models. Substantial investments in these models underscore their potential, as these corporations harness foundation models to augment various facets of their operations, setting a benchmark for other sectors.
Insights from industry leaders at Google, Microsoft and IBM, alongside academic institutions, provide a rich tapestry of knowledge and perspectives.
Percy Liang, a director of the Center for Research on Foundation Models, emphasised in this article that foundation models like DALL-E and GPT-3 herald new creative opportunities and novel interaction mechanisms with systems, showcasing the innovation that these models can bring to the table. He also mentions potential risks of such powerful models.
At the ICCV 2023 conference, held this year in Paris, foundation models were a very present topic. William T. Freeman, Professor of Computer Science, MIT, talked about the foundation models in his talk in QUO VADIS Computer Vision workshop. He cited reasons why he does not like foundation models as an academic:
- They don’t tell us how vision works.
- They’re not fundamental (and therefore not stable)
- They separate academia from industry
This highlights the importance of foundation models for the future of computer vision and their established position and pragmatic aspect of those models focusing on performance.
IBM Research posits that foundation models will significantly expedite AI adoption in business settings. The general applicability of these models, enabled through self-supervised learning and fine-tuning, allows for a wide range of AI applications, thereby accelerating AI deployment across various business domains.
Microsoft Research highlights that foundation models are instigating a fundamental shift in computing research and across various scientific domains. This shift is underpinned by the models’ ability to fuel industry-led advances in AI, thereby contributing to a vibrant and diverse research ecosystem that’s poised to unlock the promise of AI for societal benefit while addressing associated risks.
Experts also underscore the critical role of computer vision foundation models in solving real-world applications, emphasising their adaptability to a myriad of downstream tasks due to training on diverse, large-scale datasets. Moreover, foundation models like CLIP enable zero-shot learning, allowing for versatile applications like classifying video frames, identifying scene changes and building semantic image search engines without necessitating prior training.
In another workshop of ICCV 2023, BigMAC: Big Model Adaptation for Computer Vision, the robustness of the CLIP model on the popular ImageNet benchmark was discussed. In conclusion, thanks to training on a large, versatile dataset means that zero-shot predictions of the CLIP model are less vulnerable to data drift than popular CNN models trained and fine tuned on imageNet. In this recording of Ludwig’s presentation different ways to preserve CLIP robustness while fine-tuned are discussed.
On a side note, the ICCV conference was quite an event. With five days of workshops, talks and demos! Big tech companies such as Meta marked their presence with impressive hubs, answering attendees’ questions. Numerous poster sessions gave us a chance to interact with authors and select some ideas we would like to contribute to the tech stack at Adevinta.
In the subsequent sections, we will dig into real-world instances, underscoring their impact on e-commerce and elaborate how investing in this technology can galvanise collaboration and innovation across various teams within a company.

Real-World Adoption of foundation models
Major tech companies have paved the way in producing and distributing ready-to-use foundation models, which are now being utilised by various businesses to enhance or create new products for tech-savvy consumers.
E-commerce and retail
In the sphere of e-commerce, companies like Pinterest and eBay, have invested in deep learning and machine learning technologies to enhance user experiences. Pinterest has developed PinSage for advertising and shopping recommendations and a multi-task deep metric learning system for unified image embedding to aid in visual search and recommendation systems. eBay, on the other hand, utilises a convolutional neural network for its image search feature, “Find It On eBay.”
Computer vision applications are transforming e-commerce, aiding in creating seamless omnichannel shopping experiences. When it comes to the importance of visuals in shopping experiences, a study by PowerReviews found that 88% of consumers specifically look for visuals submitted by other consumers prior to making a purchase.
Broader tech industry
In the broader tech industry, Microsoft has introduced Florence, a novel foundation model for computer vision. The underlying technology of foundation models is designed to provide a solid base that can be fine-tuned for various specific tasks, an advantage that has been recognised and harnessed by industry giants.
Take Copenhagen-based startup Modl.ai for instance, which relies on foundation models, self-supervised training and computer vision for developing AI bots to test video games for bugs and performance. Such applications demonstrate the versatility and potential of foundation models in different sectors.
The practical implementations of foundation models in these different sectors underscores their potential to drive innovation, enhance user experiences and foster cross-functional collaboration within and beyond the e-commerce spectrum. The flexibility and adaptability of foundation models, as demonstrated by these real-world examples, make them a valuable asset for companies striving to stay ahead in the competitive e-commerce landscape.
Investing in foundation models: Cost-benefit analysis
The investment in foundation models for computer vision transcends the mere financial outlay. It encapsulates a strategic foresight to harness advanced AI technologies for bolstering e-commerce operations.
Investing in foundation models for computer vision in e-commerce does entail upfront costs such as acquiring computational resources and the requisite expertise. OpenAI’s GPT-3 model, for example, reportedly cost $4.6M to train. According to another OpenAI report, the cost of training a large AI model is projected to rise from $100M to $500M by 2030.
However, the potential benefits could justify the investment. For instance, the global visual search market, which is significantly powered by computer vision technology, is projected to reach $15 billion by 2023. Early adopters who incorporate visual search on their platforms could see revenues increase by 30%. The computer vision market itself is soaring with an expected annual growth rate of 19.5%, predicted to reach a value of $100.4 billion by 2023.
These figures suggest that the integration of computer vision, particularly through foundation models, can be a lucrative venture in the long-term. Consumers are increasingly leaning towards platforms that offer visual search and other AI-driven features. Therefore, the cost of investment could be offset by the subsequent increase in revenue, enhanced user engagement and improved operational efficiency brought about by the advanced capabilities of foundation models in computer vision.
“Foundation models cut down on data labelling requirements anywhere from a factor of like 10 times, 200 times, depending on the use case”— Dakshi Agrawal, IBM fellow and CTO of IBM AI
Moreover, the global computer vision market, which encompasses technologies enabling such visual experiences, is expected to grow substantially, indicating the increasing importance of investment in visual technologies for retail and e-commerce. The role of visual AI, which includes computer vision, is also highlighted in how it’s changing omnichannel retail, showcasing the intertwined relationship between visual technology and enhanced shopping experiences across channels.
Examples of application of foundation models in e-commerce
Because of their pre-training on expansive datasets, foundation models in computer vision bring a treasure trove of capabilities to the table. The pre-trained nature of foundation models significantly accelerates the deployment of computer vision applications in e-commerce, as they require less data and resources for fine-tuning compared to training models from scratch. Let’s illustrate this through real-world examples within the e-commerce sector.
- Product Categorisation: Leveraging a foundation model for automated product categorisation can be a time and resource-saver.
- Visual Search: Implementing visual search features can be expedited with foundation models. Their pre-trained knowledge can be leveraged to recognise fashion or product trends, making visual search more intuitive.
- Counterfeit Detection: Counterfeit detection is a complex task; however, with a foundation model, the pre-existing knowledge about different objects can be fine-tuned to identify subtle discrepancies between genuine and counterfeit products
- Moderation: Detection of unwanted or harmful content can be done through a classification head added on top of image embeddings generated by a foundation model.
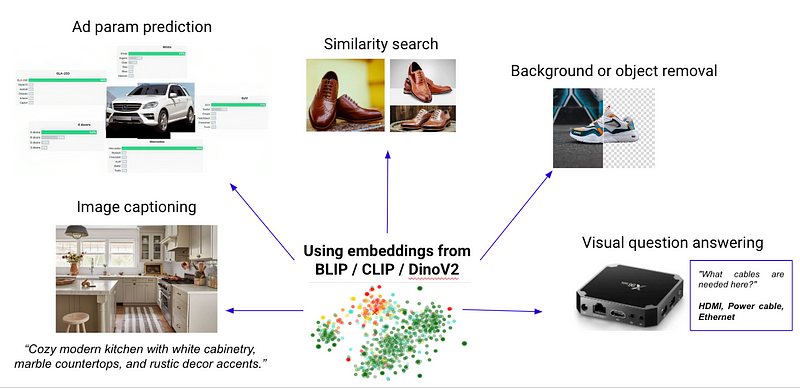
Beyond these examples, foundation models also hold promise in enhancing user experiences in recommendation systems and augmented reality (AR) shopping.
Most of this use-case could be applied to Adevinta marketplaces or replace existing services based on more traditional models.
Empowering teams across the e-commerce spectrum
Foundation models in computer vision open up avenues for fostering cross-functional collaboration, expediting product development, and making data-driven decision-making a norm across an e-commerce enterprise. Let’s delve into how these models can act as catalysts in harmonising the efforts of various teams and speeding up the journey from conception to market-ready solutions.

Accelerating the product development cycle
The pre-trained nature of foundation models significantly cuts down the time traditionally required to develop, train and deploy machine learning models. This acceleration in the product development cycle is invaluable in the fiercely competitive e-commerce market, where being the first to introduce innovative features can provide a substantial competitive edge. Moreover, the resource efficiency of foundation models ensures that teams can iterate and improve upon models swiftly, aligning with dynamic market trends and customer expectations.
Stepping stone to broader business objectives
Foundation models can act as a springboard towards achieving broader business goals such as sustainability and promoting the second-hand goods trade. By enabling smarter product listings and verifications through image recognition and visual search capabilities, these models can streamline the process of listing and verifying second-hand goods. This, in turn, promotes a circular economy, encouraging the reuse and recycling of products, which aligns with the sustainability goals of many modern e-commerce platforms.
Challenges and overcoming strategies
Incorporating foundation models for computer vision within an e-commerce setting comes with a range of challenges, but with the right strategies, these hurdles can be navigated to unlock the models’ full potential.
Computational requirements
Foundation models are computationally intensive due to their large-scale nature, which necessitates significant computational resources for training and fine-tuning. The good news is that, once the substantial work of domain-learning or fine tuning is done, numerous teams and projects can benefit from the foundation model with minimal additional effort and cost.
Bias and fairness
Foundation models may inherit biases present in the training data, which can lead to unfair or discriminatory behaviour. For instance, DALL-E and CLIP have shown biases regarding gender and race when generating images or interpreting text and images. Implementing robust data preprocessing and bias mitigation strategies will help to address potential biases in training data.
Interpretability and control
Understanding and controlling the behaviour of foundation models like CLIP remains a challenge due to their black-box nature. This makes it difficult to interpret the models’ predictions, which is a hurdle in applications where explainability is crucial. CRFM released recently a Foundation Model Transparency Index “scoring 10 popular models on how well their makers disclosed details of their training, characteristics and use.”
Foundation models, if widely adopted, could introduce single points of failure in machine learning systems. If adversaries find vulnerabilities in a foundation model, they could exploit these weaknesses across multiple systems utilising the same model.
Foundation models are not the answer to all machine learning problems.
“Foundation models are neither ‘foundational’ nor the foundations of AI. We deliberately chose ‘foundation’ rather than ‘foundational,’ because we found that ‘foundational’ implied that these models provide fundamental principles in a way that ‘foundation’ does not. (…) Further, ‘foundation’ describes the (role of) model and not AI; we neither claim nor believe that foundation models alone are the foundation of AI, but instead note they are ‘only one component (though an increasingly important component) of an AI system.’”
— the Stanford Institute for Human-Centred AI founded the Center for Research on Foundation Models (CRFM), 2021
Conclusion
The transformative potential of foundation models in computer vision is unmistakable and pivotal for advancing the e-commerce domain. They encapsulate a significant stride towards creating smarter, more intuitive and user-centric online shopping experiences. The notable successes of early adopters, alongside the burgeoning global visual search market, exhibit the financial promise inherent in embracing these models.
The real-world implications extend beyond just improved product discovery and categorisation, to fostering a sustainable trading ecosystem for second-hand goods. The expertise and investment in these models can expedite the product development cycle, encourage data-driven decision-making and stimulate cross-functional collaboration across various company departments.
However, it’s crucial to acknowledge the technical and ethical challenges that come with the deployment of foundation models. The computational costs, potential biases and the necessity for robust infrastructures demand a well-thought-out strategic approach. Yet, with the right investment in computational infrastructure, continuous learning and a commitment to ethical AI practices, these hurdles can be navigated successfully.
While the promise of foundation models in computer vision is evident, discerning which model will perform optimally with your specific data remains a complex challenge.
This uncertainty underscores the vital need for comprehensive benchmarks that can guide businesses in selecting the most appropriate model. Investing time in testing and evaluation is crucial, as it enables a more informed decision-making process. A recent study highlighted in the article “A Comprehensive Study on Backbone Architectures for Regular and Vision Transformers” delves into this subject by testing different model backbones across a range of downstream tasks and datasets. Such research is invaluable for businesses looking to capitalise on foundation models, as it provides critical insights into model performance and applicability, ensuring that their investment in AI is both strategic and effective.
In Adevinta, as an e-commerce leader, we are evaluating the pros and cons of foundation models to best leverage their potential within our company. In Cognition, we are also working on internal benchmarks that will help to chose right foundation model for the task, estimate ressources needed and showcase its potential performance on the marketplace data.
With industry behemoths and experts leading the era of foundation models, the call to action for e-commerce directors is clear: Embrace the paradigm shift that foundation models represent, and consider them as a long-term strategic asset for maintaining a competitive edge in the rapidly evolving e-commerce landscape.
Check out this mine of knowledge about foundation models: https://cs.uwaterloo.ca/~wenhuche/teaching/cs886/