Beyond denoising - rethinking inference-time scaling in diffusion models
Rethinking how diffusion models use compute at inference time — moving beyond denoising steps to noise search and verifier-guided generation.
 </span>
</span>
Generative AI is experiencing a paradigm shift. While early breakthroughs in diffusion models emphasized training-time scaling — bigger models, more data, and longer training — recent research suggests that inference-time scaling might be an equally powerful lever for improving generation quality. Unlike static architectures, diffusion models offer the unique ability to allocate compute dynamically during sampling, yet standard techniques (like increasing denoising steps) hit diminishing returns.
Maq et al. (2025) challenge this bottleneck, proposing that inference-time compute should be viewed not as a simple iteration counter but as a search problem — one where strategically refining injected noise can unlock better outputs. This perspective fundamentally reframes how we think about sample generation, drawing intriguing parallels with search-driven optimizations in Large Language Models (LLMs), such as tree-of-thoughts prompting or best-of-n decoding.
Are we witnessing the emergence of an active generation paradigm, where models don’t just passively map noise to images but dynamically explore pathways to the best output?
Why scaling matters in Generative AI
Let me introduce some context first.
The success of large generative models — whether in text (LLMs like GPT-4), images (Stable Diffusion, DALL·E), or even video and audio — rests on a simple but powerful idea:
More compute → Better results.
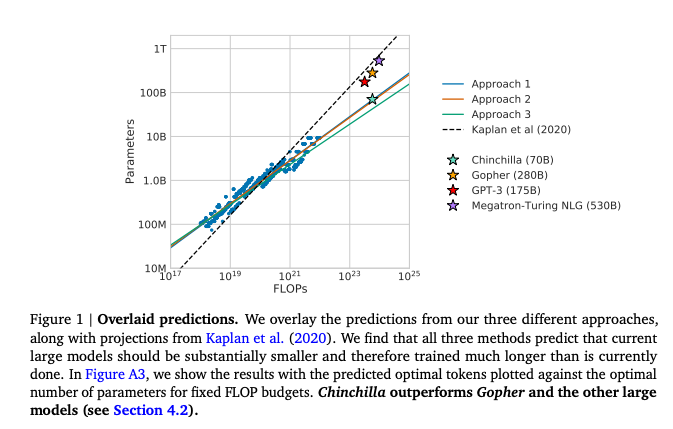
This principle, known as scaling laws, tells us that as we increase model size, training data, and compute power, generative models tend to improve in a predictable way.
 </span>
</span>
However, until recently, research on scaling has focused almost exclusively on training. The assumption has been:
- Train a bigger model on more data → get better outputs.
- Once trained, the model is fixed — inference simply runs it as-is.
But what if we could make models smarter at inference time, allowing them to refine their outputs dynamically?
Scaling in LLMs
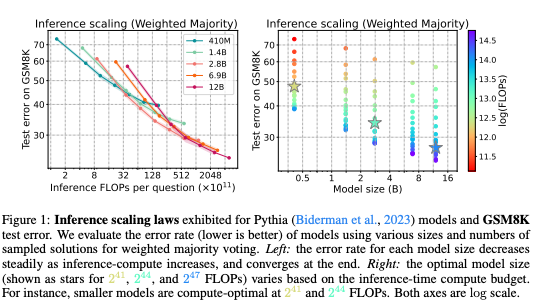
In the world of Large Language Models (LLMs), researchers have recently found that performance can improve even after training is complete, simply by allocating more compute at inference time.
This is done through:
- Search-based decoding (e.g., “best-of-n” sampling, tree-of-thoughts, reranking).
- Iterative refinement (models generating multiple responses and selecting the best).
- Verifier-guided outputs (using reward models like RLHF to optimize responses).
These techniques allow LLMs to generate higher-quality, more accurate, and more contextually relevant outputs without retraining.
 </span>
</span>
There are numerous great ressources on scaling laws for LLM, I recommend you check these ones out:
Scaling Laws for LLMs: From GPT-3 to o3 _Understanding the current state of LLM scaling and the future of AI research…_cameronrwolfe.substack.com
Chinchilla data-optimal scaling laws: In plain English _Important: This page summarizes data scaling only, using tokens to parameters as a ratio, and as derived from large…_lifearchitect.ai
OpenAI’s Strawberry and inference scaling laws _OpenAI’s Strawberry, LM self-talk, inference scaling laws, and spending more on inference. Coming waves in LLMs._www.interconnects.ai
What about Diffusion Models?
Diffusion models — used in AI-generated art, photorealistic synthesis, and video generation — have a built-in way to allocate compute at inference:
- Instead of producing an image in one step (like a GAN), they start from random noise and progressively refine it over multiple steps.
- The number of denoising steps (or NFEs, Number of Function Evaluations) determines output quality vs. compute cost.
 </span>
</span>
If you need to better understand diffusion models and denoising, here are some great ressources:
How Diffusion Models Work - DeepLearning.AI _Learn and build diffusion models from the ground up, understanding each step. Learn about diffusion models in use today…_learn.deeplearning.ai
What are Diffusion Models? _Updated on 2021-09-19: Highly recommend this blog post on score-based generative modeling by Yang Song (author of…_lilianweng.github.io
==> But here’s the problem: Simply increasing denoising steps only helps up to a point. Beyond a certain threshold, performance gains flatten out — more steps don’t improve quality much.
Maq et al. (2025) propose a new way forward:
Instead of blindly adding denoising steps, we should actively search for better noise to start with.
This idea reframes inference-time scaling not as a matter of iteration count, but as a search problem — one that could make diffusion models far more powerful and efficient.
The limits of traditional inference scaling
Scaling inference-time compute in generative models isn’t new, but its limitations have been stark. Most diffusion models operate under a straightforward assumption: more denoising steps = better samples. While this holds in early iterations, studies have shown that performance gains flatten quickly beyond a certain number of denoising function evaluations (NFEs).
Maq et al. (2025) provide empirical evidence of this plateau, reinforcing what past work (e.g., Karras et al., 2022) has hinted at — more iterations introduce approximation errors and discretization artifacts, limiting the benefits of brute-force step scaling. This raises a critical question:
 </span>
</span>
If adding more denoising steps isn’t the answer, where should we invest our compute budget instead?
Their proposed solution: optimize the starting noise itself. Not all noise samples are equal — some lead to better generations than others. By reframing sample generation as a search over noise candidates, the model can actively seek higher-quality results rather than blindly committing to a single path.
This shift from passive denoising to active search echoes trends in LLMs, where inference-time optimizations (e.g., re-ranking outputs, iterative reasoning) have led to significant performance boosts without retraining. Could similar techniques unlock new frontiers for diffusion models?
The Search Paradigm
At the heart of Maq et al.’s framework is a two-axis search strategy:
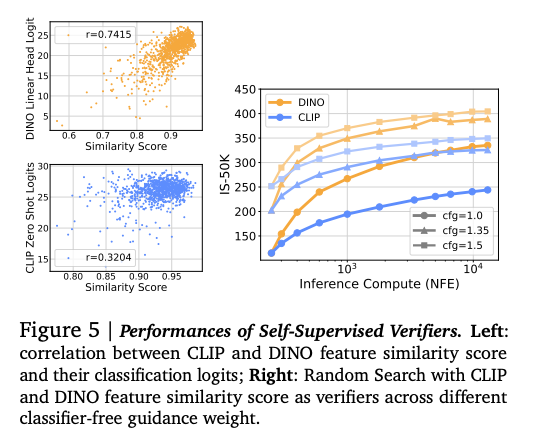
Verifier Functions: Instead of passively denoising noise into images, a verifier scores generated samples, helping guide search toward higher-quality outputs. The paper explores three types:
- Oracle Verifiers (ideal but impractical, using ground-truth FID or IS scores)
- Supervised Verifiers (pretrained classifiers like CLIP)
- Self-Supervised Verifiers (consistency-based scoring without external labels)
 </span>
</span>
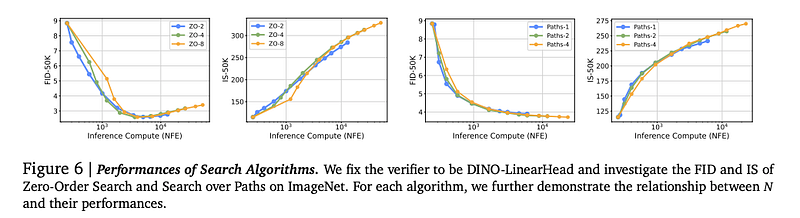
Search Algorithms: Instead of iterating endlessly on a single noise sample, the model actively evaluates multiple noise candidates and refines the search:
- Random Search: Generate multiple samples and pick the best (best-of-n selection).
- Zero-Order Search: Iteratively refine noise candidates using verifier feedback.
- Search Over Paths: Adjust noise at intermediate steps, treating generation as a trajectory exploration rather than a fixed path.
 </span>
</span>
Inference-time scaling is no longer just about running a fixed pipeline more times — it’s about making smarter choices along the way.
My thoughts
Maq et al.’s approach is an exciting step forward, but it also raises critical challenges:
Bias: Who decides what’s “better”?
While the paper demonstrates impressive gains, the choice of verifier is non-trivial. Verifier models (like CLIP or ImageReward) come with built-in biases — favoring certain aesthetics, object distributions, or stylistic preferences. This leads to potential mode collapse, where optimizing too aggressively for a specific verifier reduces overall diversity.
A striking analogy exists in LLMs: when models are fine-tuned on reward functions like RLHF, they can start overfitting to human preferences rather than maintaining broad generalization. This is a serious concern for diffusion models — will optimizing noise for a verifier ultimately reduce creative variation?
Compute cost: Is this scalable?
While this approach sidesteps retraining, it dramatically increases inference costs.
- Random search scales linearly with the number of candidate samples.
- Zero-order search requires iterative evaluations, compounding compute needs.
- Path-based search introduces additional denoising passes.
For real-time applications like interactive art generation, these search-based methods might be impractical. Future research should explore ways to compress the search process or pretrain lightweight noise-ranking networks to reduce computational overhead.
Does search capture complex prompts?
A major limitation of diffusion models today is their struggle with compositional prompts (e.g., “a cat wearing sunglasses sitting on a skateboard in front of the Eiffel Tower”). The search-based approach optimizes local noise variations — but does it help with complex scene composition?
If not, we might need hierarchical search strategies — coarse-to-fine optimizations that first establish global structure before refining details.
The future of adaptive generation
Maq et al. (2025) mark an important shift in how we think about inference-time resource allocation. Their work suggests that diffusion models can dynamically improve themselves at generation time, similar to how LLMs refine responses through iterative reasoning and ranking.
This brings us to a bigger question:
Could generative models move beyond static sampling pipelines into adaptive generation loops?
Imagine diffusion models that:
- Dynamically adjust noise injection based on scene complexity
- Leverage multi-step verifier feedback to iteratively improve object coherence
- Incorporate user-guided search, allowing interactive control over generation
Rather than a fixed “noise-to-image” pipeline, we might be moving toward an era where generative models actively explore multiple solutions before committing to a final output — more akin to an artist refining a painting rather than a one-shot rendering process.
Conclusions
The insights from Maq et al. (2025) suggest that inference-time compute can be used far more intelligently than previously assumed. By treating sample generation as an optimization problem over noise, rather than just a denoising pipeline, they demonstrate a scalable approach to boosting performance without retraining.
However, open questions remain — how do we mitigate verifier bias? Can we make this efficient enough for real-time applications? And most importantly, how do we ensure that search strategies don’t sacrifice creativity for optimization?
Regardless, one thing is clear: inference-time search marks the beginning of a new, more dynamic era for diffusion models.