Mastering Named Entity Recognition (NER) in Data Science
Extracting Keywords from Medium Articles Using SpaCy
Skills
- NLP
- Python
- machine learning
- NER
- language models
Context of development of a keyword extraction application using NLP language model
Named Entity Recognition, often abbreviated as NER, has gained traction as a critical tool for extracting meaningful insights from text data. Whether you’re diving into data science projects or exploring the cutting edge of AI applied to language, understanding how to utilize NER is essential. In this post, I’ll walk you through a practical example of using SpaCy, a go-to library for NLP, to detect keywords from Medium articles. But first, let’s explore why NER is becoming a must-have skill in the data science and engineering toolbox.
Inspired by a solution developed for a customer in the Pharmaceutical industry, we presented at the EGG PARIS 2019 conference an application based on NLP (Natural Language Processing) and developed on a Dataiku DSS environment.
More precisely, we trained a deep learning model to recognize the keywords of a blog article, precisely from Medium blogging platform.
By automatically generate tags and/or keywords, this approach enables personalized content recommendations, improving user experience by aligning content with reader expectations. The method holds significant potential, particularly for automated text analysis of complex documents, including scientific papers and legal texts.
To showcase its functionality, we integrated a voice command feature using Azure’s cognitive services API. The speech to text module translates spoken queries into text, which is then processed by the algorithm. The output is a recommendation of articles, classified by relevance according to the field of research.
In this article, I’ll walk you through our approach to creating the underlying NLP model.
[To view the comments, please enable subtitles] A video that illustrates our web application created for the EGG Dataiku 2019 conference
Why Extract Keywords from Medium Blog Articles with AI ?
Medium has two categorization systems: tags and topics.
Topics are predefined by the platform and correspond to broad categories like data science or machine learning. Authors have no control over these.
Tags, on the other hand, are keywords selected by the author, with a maximum of five tags per article. These tags help increase the visibility of the article but often may not accurately reflect the content. For instance, tags like “TECHNOLOGY,” “MINDFULNESS,” or “LIFE LESSONS” might make an article easier to find but can complicate the reader’s search for specific content.
Our approach aims to improve this by automatically tagging articles, increasing their relevance. With these “new tags” or “keywords,” searching for articles becomes more efficient.
Going further, this method could be used to build a recommendation system that suggests related articles based on the one you’re currently reading or aligned with your reading habits.
The NER (Named Entity Recognition) approach
Using the NER (Named Entity Recognition) approach, we can extract entities across various categories. Several pre-trained models, like en_core_web_md can recognize entities like people, places, dates, etc.
For example, in the sentence “I think Barack Obama met founder of Facebook at occasion of a release of a new NLP algorithm.”, the en_core_web_md model detects “Facebook” and “Barack Obama” as entities.

Dependency graph: result of line 9 (# 1)

Entity detection: result of line 10 (# 2)
With some annotated data, we trained the algorithm to detect this new entity type.
The concept is straightforward: an article tagged with “Data Science,” “AI,” “Machine Learning,” or “Python” might still cover vastly different technologies. Our algorithm is designed to detect specific technologies mentioned in the article, such as GANs, reinforcement learning, or Python libraries, while still recognizing places, organizations, and people.
During training, the model learns to identify keywords without prior knowledge. For example, it might recognize “random forest” as a topic, even if it wasn’t in the training data. By analyzing other algorithms discussed in articles, the NER model can identify phrase patterns that indicate a specific topic.
The machine learning language model behind
SpaCy Framework for NLP
SpaCy is an open-source library tailored for advanced natural language processing in Python. It’s built for production use and helps create applications that process large volumes of text. SpaCy can be used to build information extraction systems, natural language understanding systems, or text preprocessing pipelines for deep learning. Among its features are tokenization, parts-of-speech (PoS) tagging, text classification, and named entity recognition.
SpaCy offers an efficient, statistical system for NER in Python. Beyond the default entities, SpaCy allows us to add custom classes to the NER model and train it with new examples.
SpaCy’s NER model is based on Convolutional Neural Networks (CNNs). For those interested, more details on how SpaCy’s NER model works can be found in the video below:
Training data
To train our model to recognize tech keywords, we scraped some Medium articles through web scraping.
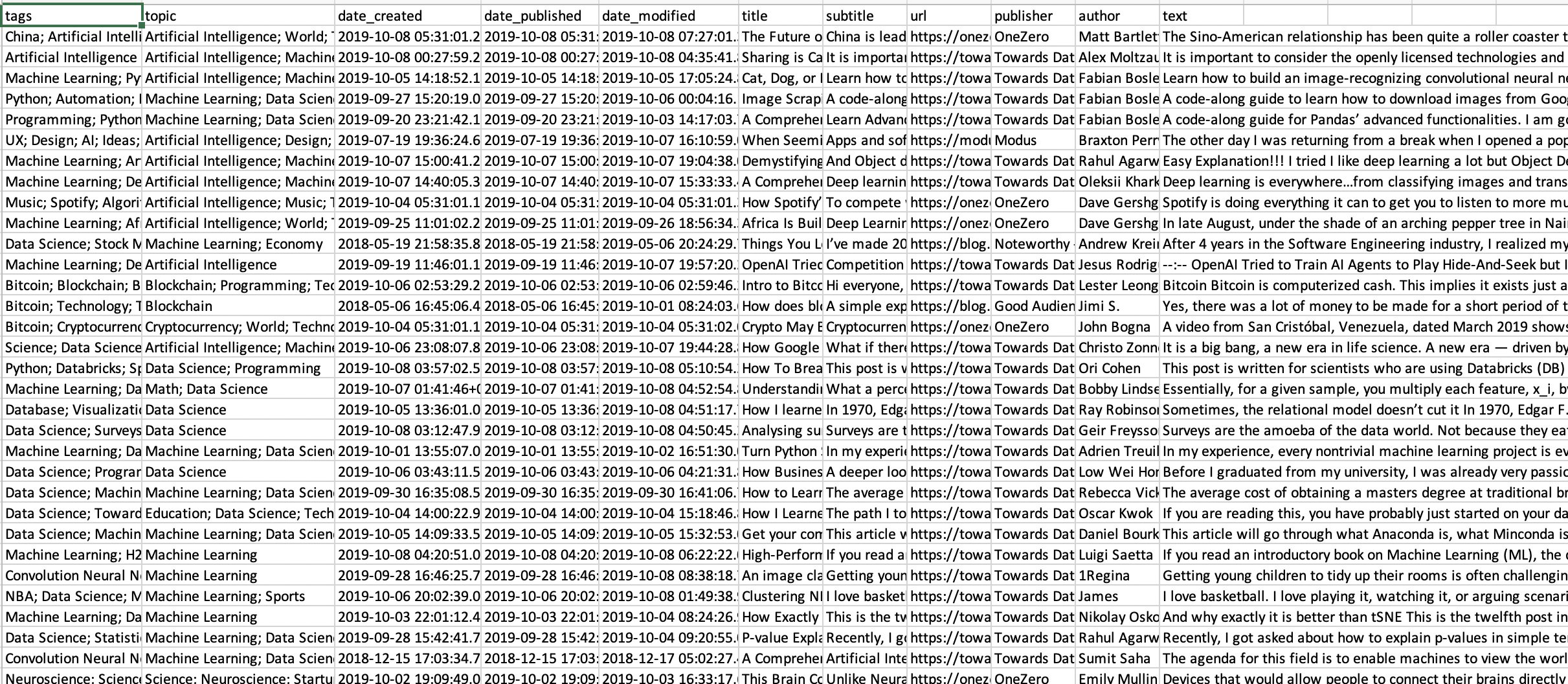
An extract from the table containing the contents of the medium articles
The text of each article was split into sentences for easier annotation.
For NER annotation, there are tools like Prodigy, but we opted for a simple spreadsheet where we manually marked the entities in dedicated columns.

With around twenty articles (~600 sentences), our model began to show promising performance, achieving over 0.78 accuracy on the test set. We separated the train and test data to evaluate the model effectively.

TRAIN_DATA_ALL =list(train_table.apply(lambda x : mark_targets(x, ['ORG', 'PERSON', 'LOC', 'TOPIC', 'GPE','DATE', 'EVENT', 'WORK_OF_ART'], "sents", ['ORG', 'PERSON', 'LOC', 'TOPIC', 'GPE','DATE', 'EVENT', 'WORK_OF_ART']), axis=1))
We fine-tuned the algorithm by adjusting parameters like the number of iterations, dropout rate, learning rate, and batch size.
The NLP model assesment
In addition to the model’s loss metric, we implemented precision, recall, and F1 score to measure performance more accurately.
After training on the annotated data, the best model’s performance on our test set was quite impressive, especially considering the modest training data size (~3000 sentences).
precision : 0.9588053949903661
recall : 0.9211764705882353
f1_score : 0.9396221959858323
It is is designed to interoperate with the Python numerical and scientific libraries NumPy and SciPy.
TOPIC Python
TOPIC NumPy
TOPIC SciPyIn the Flow on DSS, the process can be summarized by the graph:
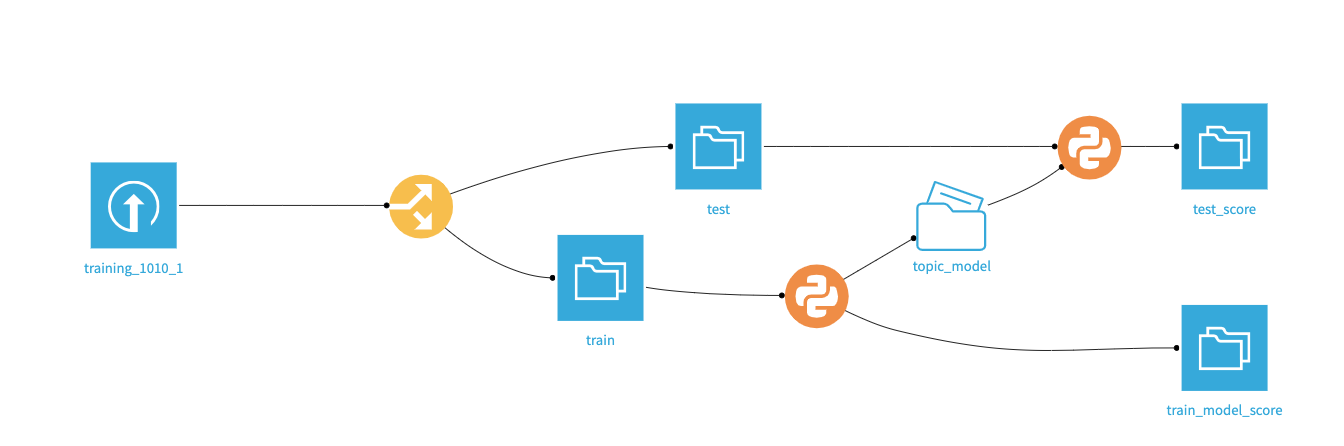
Flow on Dataiku's DSS platform: the annotated dataset is divided into train and test, the model learned on the train data is evaluated on the train and test batches.
Returning to our Barack Obama example, our algorithm now detects the NLP algorithm entity as a TOPIC, in addition to the ORG (organization), LOC (location), GPE (geopolitical entity), and DATE categories.
We have succeeded! 🚀
The next step involves incorporating the model into our recommendation system, enhancing the customization of articles offered to users based on detected topics.

The finalized model can be compiled as an independent python library (instructions here) and installed with pip. This is very practical for deploying the model in another environment and for production setup.

Exploitation of the model
Analysis of an article Medium
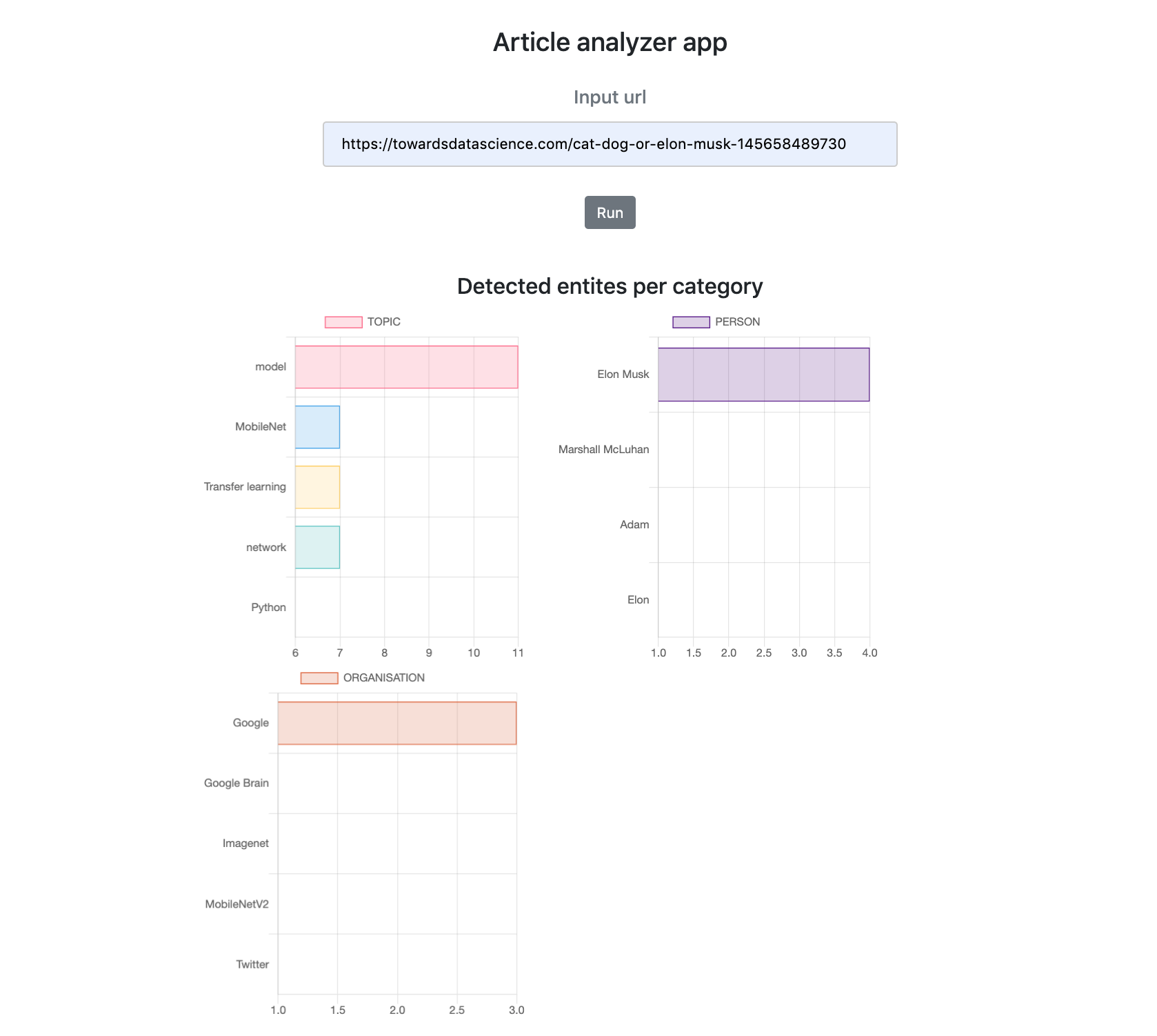
In our mini webapp, presented at the EGG, it is possible to display the most frequent entities of a Medium article.
Thus, for the article: https://towardsdatascience.com/cat-dog-or-elon-musk-145658489730, the most frequent entities were: model, MobileNet, Transfer learning, network, Python. We also detected people: Elon Musk, Marshal McLuhan and organizations: Google, Google Brain.
Inspired by Xu LIANG’s post, we also used his way of representing the relationship between words in the form of a graph of linguistic dependencies. Unlike in his method, we did not use TextRank or TFIDF to detect keywords but we only applied our pre-trained NER model.
Then, like Xu LIANG, we used the capacity of Parts-of-Speech (PoS) Tagging, inherited by our model from the original model (en_core_web_md), to link the entities together with the edges, which forms the graph below.
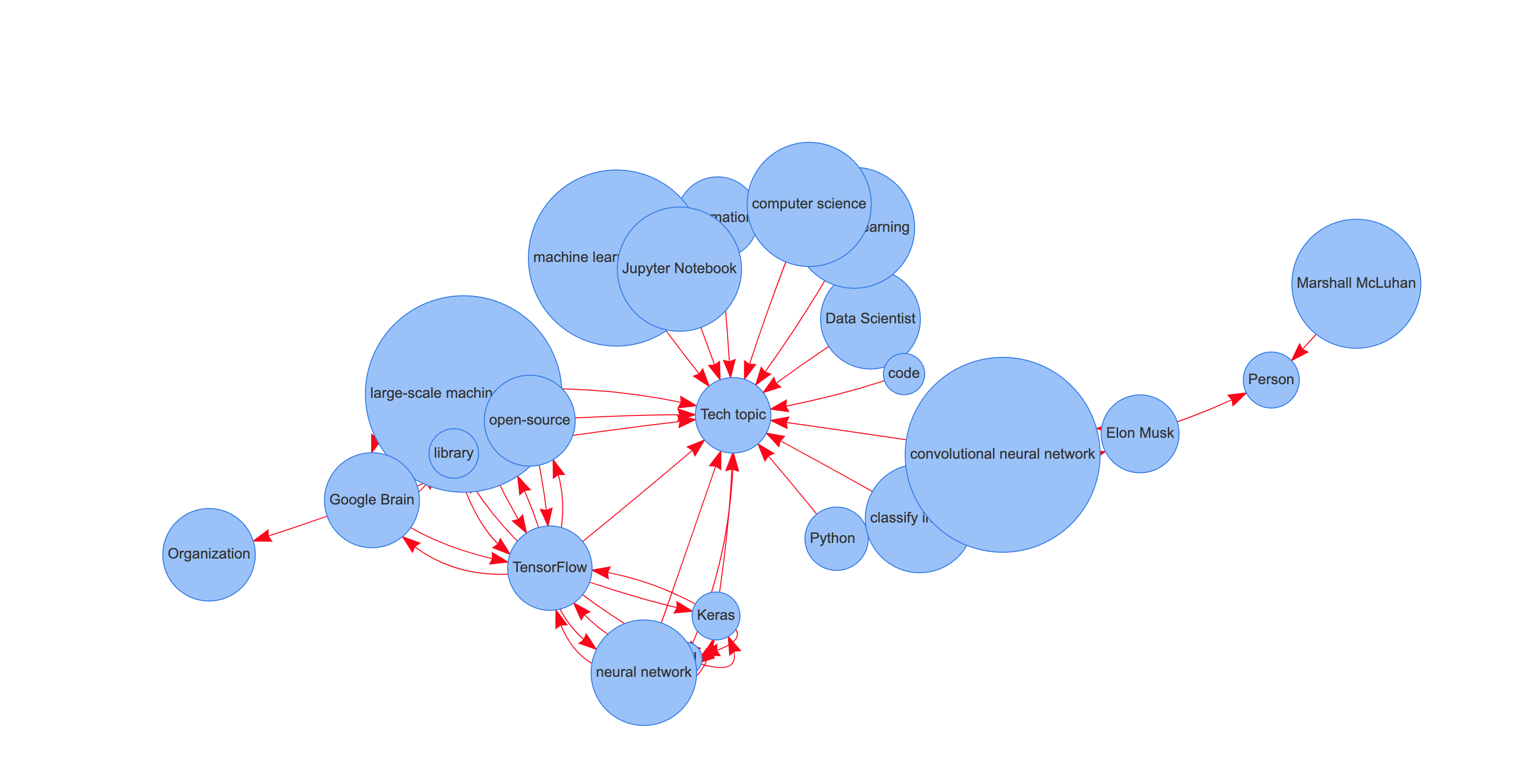
The graph of dependencies between the entities detected in the article “Cat, Dog, or Elon Musk?”
Thus, we get a graph where the keywords are placed around their category: Tech topic, Person and Organization.
This gives a quick overview of the content of a Medium article.
Here is how to get the graph from a Medium article url link:
To go further
Our Saegus Showroom including the functional webapp is coming soon. Feel free to follow our page https://medium.com/data-by-saegus to be kept informed.
The project we have outlined here can easily be transposed into the various fields of industry: technical, legal and medical documents. It could be very interesting to analyse the civil, criminal and law… with this approach for a better efficiency in the research that all legal professionals do.
Conclusions
To conclude, by recognizing topics within Medium articles, this solution represents a significant leap forward in content personalization. Whether for individual readers or professionals seeking articles on specific subjects, automatic keyword extraction offers a tailored experience. This model’s ability to classify articles based on finely-tuned NER allows for precise, relevant recommendations, improving overall user satisfaction and engagement.
We invite you to explore this exciting field and consider how such technology could be adapted to your specific needs.
Disclaimer
This article is a result of a teamwork realized at Saegus. Published originally in French at Medium.