How to choose the best image embeddings for your e-commerce business ?
Discover how to select the right image embeddings strategy — pre-trained, fine-tuned, or top-tuned — to boost visual search, product tagging, and recommendations in your e-commerce platform.
Skills
- FoundationModels
- ComputerVision
- DeepLearning
- AI
- E-commerce
- ImageSearch

Imagine uploading a picture of a designer lamp and instantly finding similar items on Leboncoin. You don’t need imagine any longer, you can go to Leboncoin app and try it out by youself !
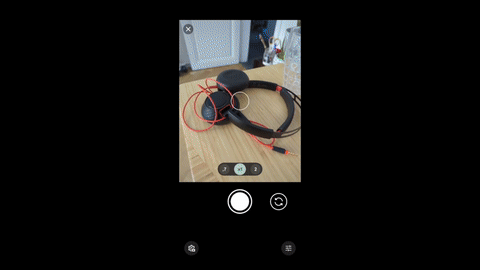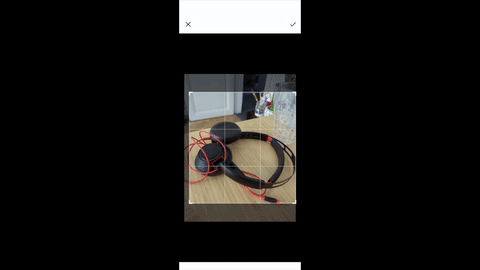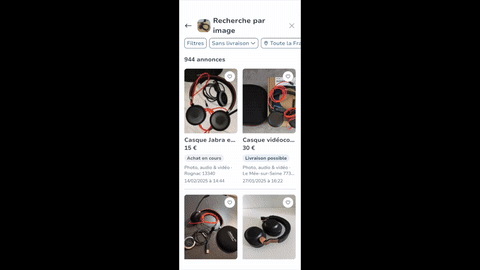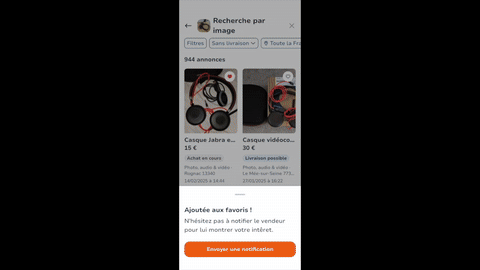
This magic happens because AI converts images into embeddings — compact numerical representations that capture the essential features of an image. These embeddings can be used for:
- Image Search: Finding visually similar products
- Product Categorization: Automatically tagging and sorting listings
- Image classification: Detect catgory, weight range, color…
- Recommendations: Suggesting related products to users
But not all embeddings are created equal. Foundation models aren’t optimized for e-commerce out of the box. You need to decide whether to fine-tune them, use them as-is, or apply a lightweight tuning approach. So, which strategy is best? That’s exactly what we set out to benchmark.
You can find the full article accepted for “Future Technologies Conference (FTC) 2025” that will happen in Munich, Germany 6–7 November 2025 on arxiv at this link.
Come to say hi if you are attending, Jeremy Chamoux will present our work there.
FTC is the world’s pre-eminent forum for reporting research breakthroughs in Artificial Intelligence, Robotics, Data Science, Computing, Ambient Intelligence and related fields. It has emerged as the foremost world-wide gathering of academic researchers, Ph.D. & graduate students, top research think tanks & industry technology developers.
The challenge: Finding the best AI model for the job
There’s no shortage of AI models that can generate image embeddings. Some are designed for general-purpose vision tasks, while others specialize in e-commerce or multimodal learning (combining images and text).

</span>
To determine the best approach for Leboncoin’s marketplace, we benchmarked three main types of AI models:
Supervised Learning Models: Trained on labeled data (e.g., images explicitly tagged with categories).
- ConvNext
- ResNet
- ViT
Self-Supervised Learning (SSL) Models: Learn patterns without labeled data, making them more flexible.
- DINO
- DINOv2
- Maws
- MAE
Contrastive Learning Models (Text-Image): Models like CLIP, which link images to text descriptions for richer representations.
- CLIP (different versions with pretraining)
- SigLIP
We also tested different supervised fine-tuning strategies to see whether adapting these models to e-commerce data would improve results.
Selecting these models families we also had in mind the possible adaption work we planned to conduct as a next step.
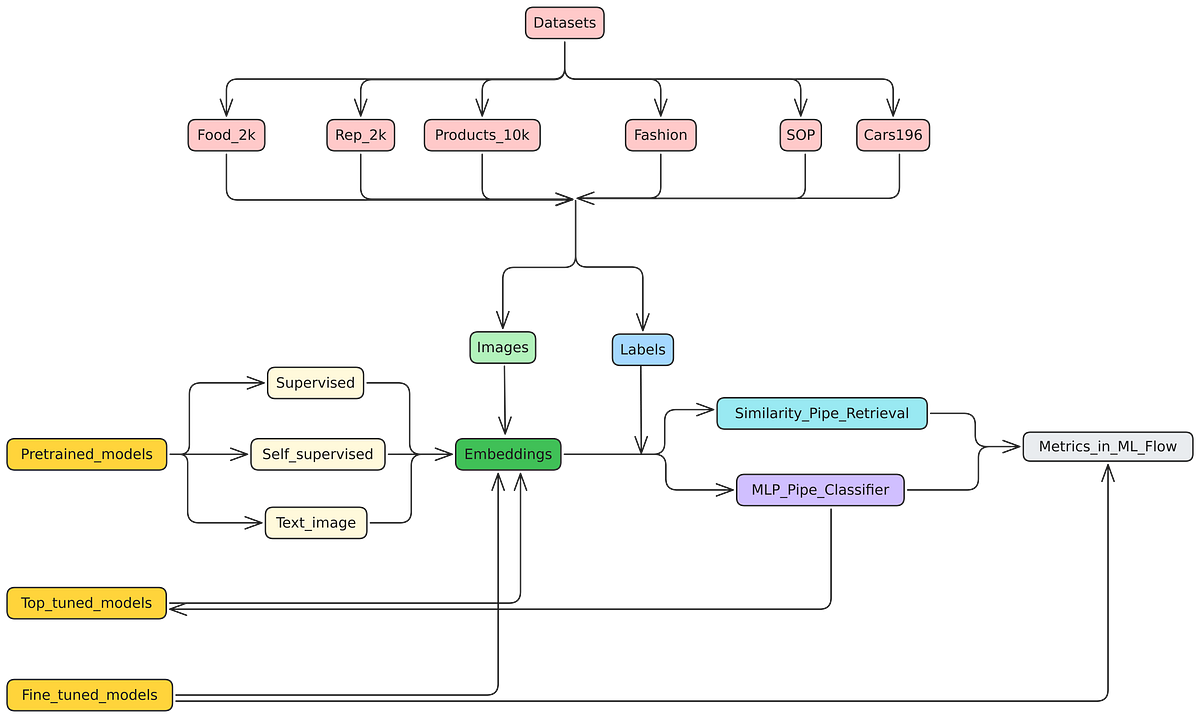
Adapting different models family requires different input data, for supervised learning we would need images and labels on a task making model learn information generic enough to reuse for different applications, for contrastive learning we would need image caption(s) pairs, while for self-supervised learning just images would be enough (which would allow us to leverage Tb of images).
</span>
How we tested AI models on e-commerce data
To ensure a fair comparison, we evaluated AI models on six real-world e-commerce datasets covering different product categories:

</span>
Key experiments we ran
Each AI model was tested on two core tasks:
- Product Classification: Can the AI correctly categorize images into predefined product types?
- Image Retrieval: Given a query image, can the AI find the most visually similar products (where similarity is defined as from the same category)?
For retrieval, we used vector search (storing embeddings in a database and finding nearest neighbors) with Millvus and evaluated the models using industry-standard ranking metrics like Mean Average Precision (MAP) and Recall@K (how often the correct product appears in the top results).
Understanding image embeddings: The three main approaches
When working with image-based AI in e-commerce, you have three primary choices for generating embeddings:
1. Pre-trained embeddings (Off-the-shelf models)
These embeddings come from large-scale models trained on general-purpose datasets like ImageNet. Examples include:
Pros: - No training required — just use them as-is - Works well for general image understanding - Ideal for companies with limited ML expertise
Cons: - May not capture e-commerce-specific nuances (e.g., distinguishing a luxury bag from a knockoff) - Suboptimal performance in fine-grained product categorization
2. Fully fine-tuned embeddings (Training on your own data)
Fine-tuning means adapting a pre-trained model to your specific e-commerce dataset by updating all of its parameters. This makes the embeddings highly specialized for tasks like product classification or search.
Pros: - Best accuracy for domain-specific tasks - Captures subtle differences in product categories
Cons: - Computationally expensive (requires GPUs, storage, and time) - Risk of overfitting, especially with small datasets - Requires ML expertise to tune hyperparameters effectively
3. Top-tuned embeddings (The sweet spot for e-commerce)
Top-tuning is a middle ground: instead of fine-tuning the entire model, we freeze the base layers and only train a lightweight classifier on top. This is much cheaper than full fine-tuning but can still provide a performance boost.
Pros: - Significant improvement over pre-trained models - Requires far fewer resources than full fine-tuning - Faster to deploy in production
Cons: - Not always as strong as fully fine-tuned models for classification tasks - Still requires some labeled data for training
Key results
 </span>
</span>
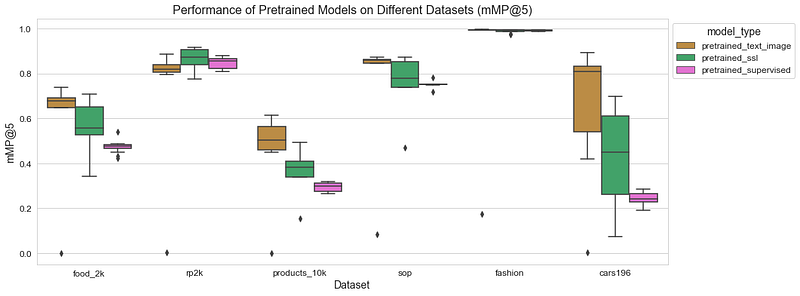
1. Different Model Types Excel in Different Scenarios
- Supervised fine-tuned models (e.g., ConvNeXt-Base, ViT-B) achieve the highest accuracy but require significant computational resources.
- Self-supervised models (SSL) (e.g., DINO-ViT, MAWS-ViT) show high variance, making them less stable but useful with top-tuning.
- Contrastive text-image models (e.g., SigLIP, Marqo, Apple CLIP) excel in retrieval tasks with minimal adaptation.
- Top-tuned models add lightweight layers to pre-trained models, often matching full fine-tuning while reducing compute costs.
- Cross-tuned models, trained on one dataset and used on another, show mixed results, performing well only when datasets share characteristics.
2. ConvNeXt-Base Leads in Supervised Fine-Tuning
- ConvNeXt-Base achieved 93% accuracy, outperforming ViT-B and DINO-ResNet50 by 3.6% in classification tasks.
- It also dominated retrieval performance on Cars196, SOP, and Fashion, but struggled on Product-10k, where ViT-B excelled.
3. ViT Models Offer Strong Generalization
- ViT-base performed consistently well across datasets, balancing accuracy and efficiency.
- ViT-large, despite being 4.6× more expensive to train than ViT-B, underperformed, suggesting dataset size impacts ViT-L’s effectiveness.
4. Self-Supervised Learning (SSL) Shows High Variance
- DINO-ViT-B and MAWS-ViT-B showed competitive performance, but SSL models exhibited 10× higher variance than supervised models.
- DINOv2 was the best-performing SSL model, but overall, SSL models were less stable without additional fine-tuning.

</span>
5. Contrastive Text-Image Models Excel in Retrieval
- SigLIP achieved state-of-the-art retrieval performance across five of six datasets, proving its versatility.
- Marqo performed strongly, particularly in Product-10k, SOP, and Fashion datasets, highlighting its effectiveness for fine-grained retrieval but in image-image retrieval it did not beat SigLip (while according to authors it beats SigLip on text-image benchmark).
- Apple CLIP ranked among the top models, excelling in RP2K and retrieval-heavy tasks.

</span>
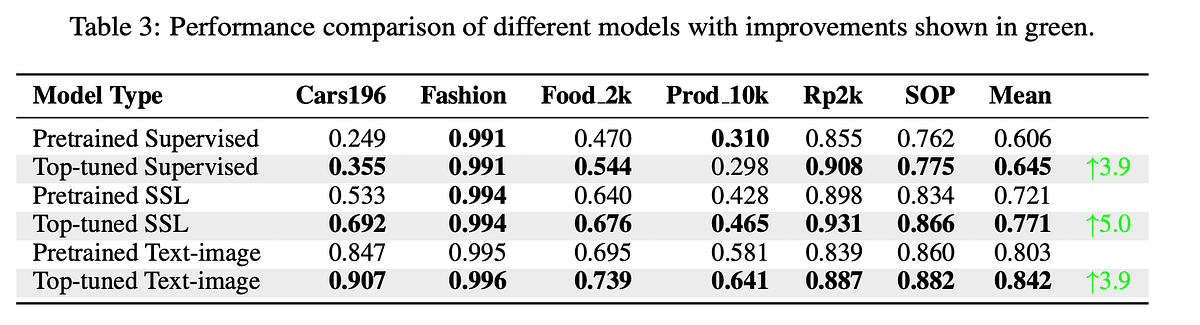
6. Fine-Tuning is Crucial, But Not Always Necessary
- Fine-tuning significantly improves retrieval accuracy, often matching or surpassing previous state-of-the-art (SOTA) benchmarks.
- Top-Tuning (adding lightweight layers) boosts self-supervised and text-image models, often matching full fine-tuning at a fraction of the computational cost.
</span>
7. Top-Tuning Shows the Biggest Gains for SSL Models
- Self-supervised models saw a 5% average performance boost with top-tuning, sometimes matching fully fine-tuned models.
- However, DINO-ResNet50 and MAE models saw performance drops with top-tuning, showing that its effectiveness depends on architecture.
</span>
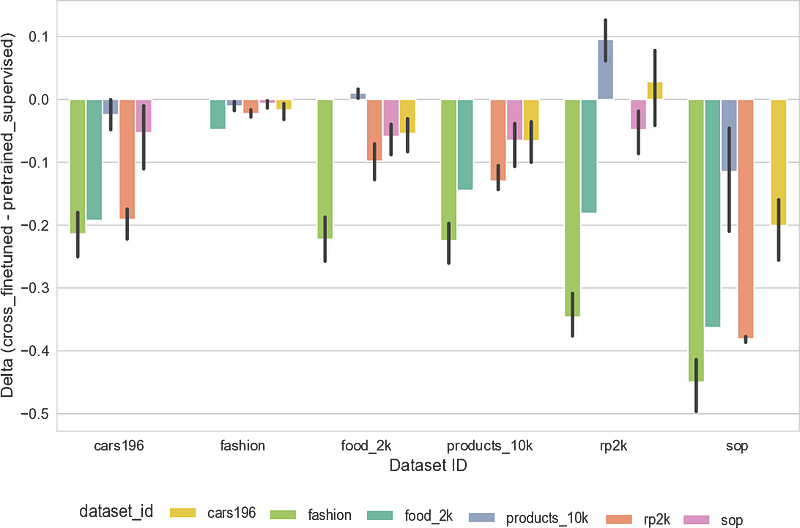
8. Cross-Tuning is Dataset-Dependent
- Cross-tuned models struggled on dissimilar datasets, with performance dropping up to -0.5 mMP@5.
- However, Cars196 fine-tuned models transferred well to RP2K, suggesting that dataset specialization plays a key role in cross-tuning success.
9. Training Time Trade-Offs Matter
- ConvNeXt and ViT-Large require the longest training times, making them less ideal for rapid deployment.
- ViT-B and ResNet50 offer strong performance with much faster training, making them efficient choices.
Practical recommendations for e-commerce AI
After humndreds of tests, here’s what we recommend for online marketplaces:
For Visual Search & Recommendations
- Use top-tuned contrastive models like SigLIP
=> They perform best in image retrieval, even without labeled data.
Pretrained contrastive models (like CLIP) perform surprisingly well retrieval. These models, originally trained for multimodal tasks, excel at image-to-image retrieval without requiring domain-specific fine-tuning. This makes them ideal for visual search applications.
For auto-tagging & categorization
- Use fully fine-tuned supervised models (ViT, ConvNeXt) when accuracy is critical
=> This is ideal for structured catalogs where precision matters.
Fine-tuning is powerful but costly. Fully fine-tuned models perform the best but require significant computational resources. If you have a dedicated ML team and the budget, this is the best approach for classification tasks.
For fast & cost-effective AI deployment
- Use pre-trained SSL models with top-tuning
=> They provide flexibility while keeping computational costs low.
Applying a lightweight classifier on frozen embeddings provides a 3.9%–5.0% improvement over pre-trained models while using a fraction of the compute required for full fine-tuning.
Takeaway: If you need a quick performance boost without massive compute costs, top-tuning is the way to go.
For cross-domain adaptation (e.g., Fashion → General Retail)
- Use cross-tuned models (trained on one dataset, applied to another)
=> This works well when datasets share similar characteristics.
Adapting embeddings from one dataset to another only works well when the datasets have similar characteristics. Otherwise, performance can degrade significantly.
What this means for Leboncoin
At Leboncoin, this research helps us make data-driven decisions on AI adoption for improving product search, recommendations, and categorization. By choosing the right AI models, we can:
- Deliver better models exploiting users images.
- Optimize AI costs by using efficient training strategies.
- Guide ML teams towards most effective strategy for the embeddings choice
This study confirms that choosing the right image embedding strategy can significantly impact e-commerce performance & ml time to market.
💡 If your business relies on image-based search, classification, or recommendations, investing in contrastive embeddings and lightweight tuning is a no-brainer. It delivers high accuracy while keeping computational costs in check.
If you’re working on image search, retrieval, or classification in e-commerce, what’s been your experience? Let’s discuss in the comments