From PCA to SSL - A personal odyssey in Data Science
Tracing the evolution - My journey through the changing landscape of machine learning
Welcome to a journey through the evolving landscape of Data Science, a journey that parallels my own academic and professional path. In this article, I will share how fundamental concepts like Principal Component Analysis (PCA) and Independent Component Analysis (ICA) have been instrumental in leading me to the field of Self-Supervised Learning (SSL).
So, why share this story? It’s not merely a chronicle of progress in Data Science; it’s a testament to the profound synergy between the foundational theories I mastered during my doctoral studies and the avant-garde techniques I am navigating now. This path hasn’t just shaped my career; it has fundamentally altered my perspective on the potential and direction of Data Science.
I hope it can inspire you, dear reader, that fundamental concepts are reborn under a different form.
We will start by looking at the basics of PCA and ICA, the building blocks of my entry into data analysis. From there, we’ll see how these methods have evolved into today’s more dynamic and autonomous SSL approaches.
What lessons did I learn in this transition? How do these experiences mirror the broader changes in the field of Data Science?
This exploration aims to provide a deeper understanding of how the field is evolving and what it means to us as practitioners and enthusiasts.
My roots in Unsupervised Learning
Discovering PCA and ICA during my PhD
Beginning my journey in Unsupervised Learning
My initial encounter with unsupervised learning occurred during my undergraduate studies, deepening significantly through my Ph.D. research at the Curie Institute. This experience wasn’t just academic; it represented my first foray into applying complex data science concepts to real-world biological data. It was here that I delved into Principal Component Analysis (PCA) and Independent Component Analysis (ICA), exploring their capabilities in a practical, research-driven environment.

Applying PCA and ICA to transcriptomic analysis
In my early systems bilolgy research days, PCA was a fundamental tool for analyzing gene expression data. Its primary function was to reduce the dimensionality of large datasets, allowing me to identify and focus on the most significant variables in the data. This method was crucial for managing the complexity of transcriptomes and extracting meaningful insights from vast amounts of data.
ICA, in contrast, served a different but equally vital role. It was instrumental in separating mixed signals in the data, enabling the identification of independent sources of variation. This technique was particularly useful in dissecting a complex gene expression pattern in tissue representing a mix of normal, cancer and immune cells, allowing for a clearer understanding of the underlying biological processes of an immune response to immunotherapy.
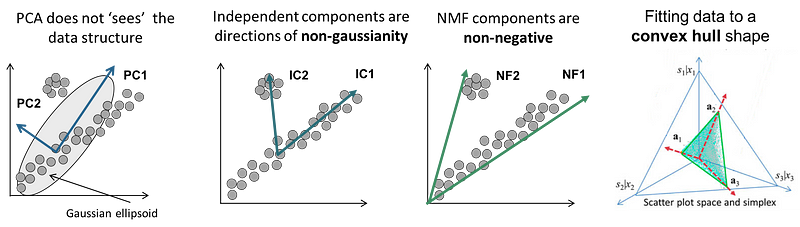
Navigating the maze: challenges and limitations

Despite their utility, both PCA and ICA have limitations, especially when applied to biological data. One major limitation of PCA is its inherent assumption of linear relationships and multivariate normal distribution of data. However, biological processes are often intricate and non-linear, and microarray gene expression measurements, for instance, tend to follow a super-Gaussian distribution, not accurately captured by PCA. This limitation becomes particularly evident when the biological questions at hand are not directly related to the highest variance in the data, a fundamental aspect of PCA’s data decomposition approach.
ICA, while effective in separating mixed signals and identifying non-Gaussian components, also presents challenges. Its results can be unstable and dependent on the number of components extracted. This is compounded by the fact that ICA does not inherently order its components by relevance, necessitating multiple runs and averaging of results to obtain robust outcomes. The high dimensionality of biological datasets often requires PCA to be used as a pre-processing step before applying ICA, which can further complicate the analysis.
Also, both approaches, belongs to the realm of statistical analysis. In a world of fast-paced innovation and deep learning, they seem covered with dust and old-fashioned.
The challenges and insights gained from working extensively with ICA during my Ph.D. significantly contributed to my expertise in machine learning. Post-Ph.D., I ventured into the field of natural language processing, applying deep learning techniques to tackle complex linguistic data. My career then led me to Adevinta, where I expanded my focus to include computer vision, leveraging deep learning in new and innovative ways. This diverse experience in ML and DL paved the way for my current exploration into Self-Supervised Learning (SSL), marking a continuous journey through the evolving landscape of artificial intelligence.
Transitioning to Self-Supervised Learning
These experiences with PCA and ICA were more than just academic exercises; they were foundational in shaping my approach to data analysis. They prepared me for the another phase of my career in Self-Supervised Learning (SSL), where I would apply the principles of unsupervised learning to even more complex and dynamic datasets, such as image datasets. The core idea of finding robust abstraction of a data object (image, dataset, text) remains common to PCA and SSL. This non-linear transition marked a significant shift from analyzing biological data to exploring the frontiers of artificial intelligence, but at the same time it is very connected in an intriguing way.
The Evolution of Unsupervised Learning
From PCA and ICA to Deep Learning
The evolution from traditional unsupervised methods like PCA and ICA to Self-Supervised Learning (SSL) in Deep Learning is a significant development in the field of machine learning. While PCA and ICA were pivotal in their time for dimensionality reduction and signal separation, they have limitations with non-linear, high-dimensional data structures common in modern datasets.
The advent of SSL in Deep Learning has revolutionized our approach to data. SSL, unlike its predecessors, leverages deep neural networks to learn from unlabeled data, extracting complex patterns and features without the need for explicit annotations. This advancement not only overcomes the constraints of labeled data but also opens new possibilities in diverse domains, ranging from natural language processing to computer vision.
SSL represents a paradigm shift, offering a more nuanced and comprehensive understanding of data. It signifies the ongoing evolution and sophistication of machine learning techniques, marking a new era in the exploration and utilization of data.
“If intelligence was a cake, unsupervised learning would be the cake, supervised learning would be the icing on the cake, and reinforcement learning would be the cherry on the cake.” — Yann LeCun
In 2019, Yann LeCun updated the above quote, changing “unsupervised learning” to “self-supervised learning,” and in 2020 he declared that self-supervised learning (SSL) is the future of machine learning (source).
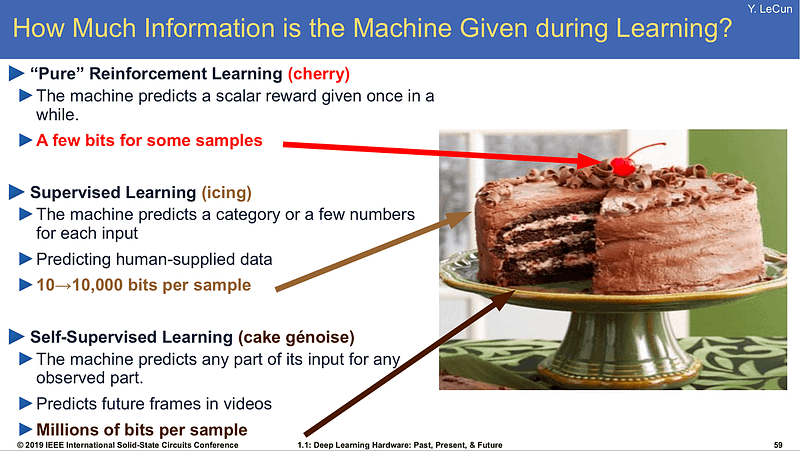
Introduction to Self-Supervised Learning (SSL)
What is SSL?
Self-Supervised Learning (SSL) represents the latest frontier in this evolutionary journey. SSL, in a sense, is a clever workaround to the challenge of labeled data scarcity. It leverages the data itself to generate its own supervision. Think of it as a student who, instead of relying solely on a teacher’s guidance, learns by exploring and questioning the world around them.
The system learns to understand and work with data by creating its own labels from the inherent structure of the data. This is a significant departure from traditional supervised learning, where models are trained on a dataset explicitly labeled by humans.
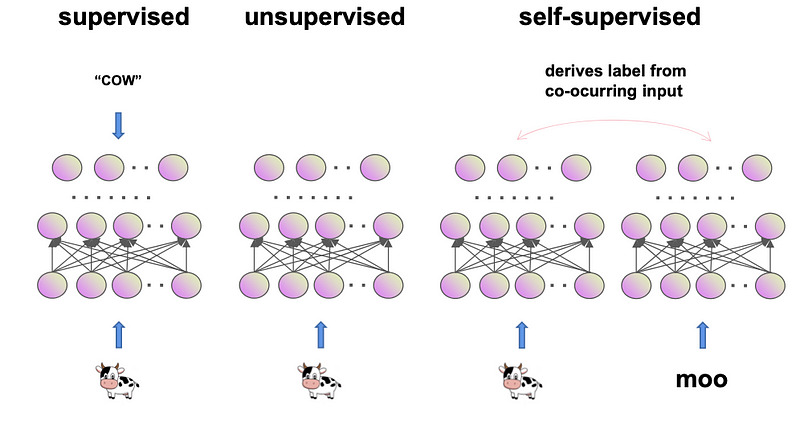
For instance, in image processing, an SSL algorithm might learn to predict missing parts of an image, or in text processing, to predict the next word in a sentence. Through these tasks, the model gains an intrinsic understanding of the structure and context of the data.
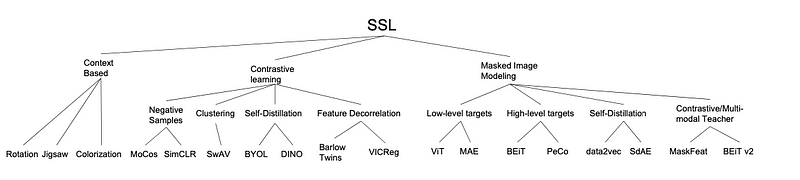
Self-Supervised Learning, a subset of unsupervised learning, has evolved dramatically, introducing various families of models, each with its unique approach to learning from unlabeled data. Here are some of the primary families of SSL algorithms:
1. Contrastive Learning Models:
- Principle: These models learn representations by contrasting positive pairs (similar or related data points) against negative pairs (dissimilar or unrelated data points).
- SimCLR (Simple Framework for Contrastive Learning of Visual Representations): Utilizes a simple contrastive learning framework for visual representations.
- MoCo (Momentum Contrast for Unsupervised Visual Representation Learning): Focuses on building dynamic dictionaries for contrastive learning in vision.
2. Predictive Learning Models:
- Principle: These models predict some parts of the data using other parts, thereby learning useful representations.
- BERT (Bidirectional Encoder Representations from Transformers): Predicts missing words in a sentence, gaining contextual understanding in NLP.
- GPT (Generative Pretrained Transformer): Predicts the next word in a sequence, learning sequential and contextual patterns in text.
3. Generative Models:
- Principle: These models learn to generate or reconstruct data, thereby understanding the distribution and structure of the dataset.
- VAE (Variational Autoencoders): Learns to reconstruct input data, capturing the probabilistic distribution.
- GANs (Generative Adversarial Networks): Involves a generator and a discriminator learning in a competitive manner to produce realistic data.
4. Clustering-Based Models:
- Principle: This approach involves clustering data points and learning representations that respect these cluster assignments.
- DeepCluster: Utilizes clustering of features and subsequent representation learning.
- SwAV (Swapping Assignments between Views): Employs a unique approach where it clusters data points and enforces consistency between cluster assignments of different augmented views of the same image.
5. Transformation Recognition Models:
- Principle: These models learn by recognizing transformations applied to the input data.
- Jigsaw Puzzles as a task: The model learns by solving jigsaw puzzles, essentially recognizing spatial relations and transformations.
- RotNet: Involves learning by recognizing the rotation applied to images.
Each of these families represents a different angle of approaching the challenge of learning from unlabeled data. Self-Supervised Learning (SSL) marks a significant evolution in machine learning, especially in the realms of deep learning. It transforms the challenge of learning from unlabeled data into an opportunity. In practice, SSL has been revolutionary, particularly in fields like natural language processing and computer vision, where it has expanded the boundaries of machine learning applications.
Limitations
SSL’s transformative potential is undeniable, but its journey to widespread industry adoption is hindered by several key challenges. The most notable is the high computational cost. Training SSL models demands significant resources, posing a barrier for smaller entities, as highlighted in industry analyses. Additionally, the technical complexity of SSL algorithms is a daunting hurdle, requiring deep expertise for effective implementation and task-specific fine-tuning.
Data quality and variety are crucial for SSL effectiveness. In data-limited or sensitive industries, SSL models face difficulties in learning efficiently. Moreover, the industry lags in developing readily usable SSL frameworks, slowing down practical application despite rapid academic progress.
Another critical aspect is the ethical and privacy implications of using large datasets essential for SSL. The industry must navigate this delicate balance to ensure ethical data utilization.
Bridge between PCA and SSL
The intriguing aspect of SSL, especially in the context of contrastive learning (CL) and its relation to PCA, is highlighted in studies such as “Deep Contrastive Learning is Provably (almost) Principal Component Analysis.” This research provides a novel perspective on CL, showing that with deep linear networks, the representation learning aspect of CL aligns closely with PCA’s principles. This connection underlines the evolutionary link from traditional statistical methods like PCA to advanced SSL techniques.
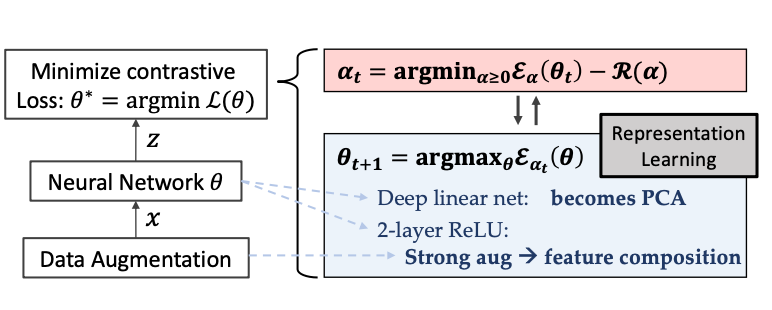
We provide a novel game-theoretical perspective of con- trastive learning (CL) over loss functions (e.g., InfoNCE) and prove that with deep linear network, the representation learning part is equivalent to Principal Component Analysis (PCA).
By leveraging deep neural networks, CL in SSL transcends PCA’s linear constraints, enabling the extraction of complex, nonlinear relationships within data. This progression from PCA to SSL illustrates how foundational data science concepts continue to shape contemporary technologies. Understanding this link allows us to appreciate SSL, particularly in deep learning, as a modern interpretation of long-standing principles in data analysis.
The transition from PCA and ICA to SSL represents a leap forward in our capacity to not just recognize but deeply comprehend patterns in data, opening new horizons in data science and beyond.
Linking the past with the present: personal perspective
My encounter with SSL

My journey into the realm of Self-Supervised Learning (SSL) was like stepping into a new world, yet one that felt strangely familiar. I first encountered SSL while expanding my horizons in the ever-evolving landscape of data science. Coming from a background heavily influenced by PCA and ICA in computational biology, the leap to SSL was both intriguing and formidable.
Initially, SSL seemed like a puzzle. It promised a more nuanced understanding of data without the explicit need for labels, a concept that was both challenging and exciting and above all very familiar. This resonated with my earlier work where we often grappled with unlabeled biological datasets. SSL’s approach of learning from the data itself, finding patterns, and using them to build more robust models, was a game changer. It was like watching the evolution of my previous work in PCA and ICA but on a more intricate and expansive scale.
Insights from the recent SOTA articles
The insights from ICCV 2023, particularly the BigMAC workshop, illuminated the recent strides in SSL. The workshop’s focus on large model adaptation for computer vision highlighted the challenges and opportunities arising from the increasing size and complexity of neural networks, especially in adapting them to novel tasks and domains.
Key talks such as Neil Houlsby’s on “Advances in Visual Pretraining for LLMs” emphasized the scalability of Vision Transformers and their growing visual capabilities, marking significant progress in visual pre-training. Ishan Misra’s discussion on leveraging SSL for scaling multimodal models demonstrated how SSL can enhance model efficiency and improve foundational multimodal models, even in the context of scarce paired data.
The session on fine-tuning pretrained models revealed crucial insights into mitigating feature distortion, a challenge often overlooked but vital for preserving the robustness and accuracy of models. Additionally, talks on controlling large-scale text-to-image diffusion models like DALL-E 2 and Imagen offered perspectives on enhancing user control in the generation process, blending training-time and inference-time techniques.
These developments at ICCV 2023 underscored SSL’s dynamic evolution and its transition from traditional PCA and ICA methodologies to more sophisticated, nuanced models capable of deeper and more intuitive data understanding.
The future of multimodal data alignment in Biology

One of the most exciting prospects brought to light at ICCV 2023, a conference rich in innovative ideas as evident in its proceedings, was the potential of AI in aligning multimodal biological data. The discussions led by pioneers like Yann LeCun, whose publications and talks have been a personal beacon for me, particularly on AI models like I-JEPA for different modalities, opened up a new realm of possibilities. This approach could revolutionize how we handle complex biological datasets, like transcriptomes, microscopy images, immunoscores, single-cell data, and proteomics.
The idea of integrating these diverse data types using advanced SSL techniques is not just a technological leap; it’s a new way of thinking about biological research. Reflecting on my journey, where resources like “Deep Learning for Biology” have been instrumental in understanding the application of deep learning in biology, I see how we’re transitioning from isolated data types to a holistic, interconnected understanding of life’s complexities. Likewise, the survey ‘Multimodal Machine Learning: A Survey and Taxonomy’ by Morency et al. has been enlightening in understanding the methodologies of multimodal data integration. These readings have not only informed my professional growth but have also mirrored the evolution of data science itself — from focusing on singular data types to embracing an integrated, multi-dimensional approach that resonates with my own professional evolution and reaffirms my belief in the transformative power of data science.
Practical implications and future directions
Applying SSL in my current projects
Integrating Self-Supervised Learning (SSL) into my work at Adevinta has been akin to embarking on an exhilarating expedition into uncharted territories of computer vision. Reding about models like DINO v2 and masked autoencoders, the versatility and transformative power of these tools continually astound me. In my role, which orbits primarily around vision classifiers and deep learning frameworks like TensorFlow and PyTorch, SSL has emerged not just as a tool but as a concept, enabling me to push for an operational paradigm shift for data users and ML/DS teams.
The Boundless Horizon of SSL
Peering into the future, I envision SSL as the an important advancement. Its prowess in harnessing the untapped potential of unlabeled data heralds a new era of possibilities. Imagine a world where SSL is the norm in data science, especially in data-rich yet label-poor realms like healthcare and finance. The implications are monumental.
Inspired by visionaries like Yann LeCun, the prospect of SSL in aligning disparate biological data types — from the intricate patterns of transcriptomics to the dynamic landscapes of proteomics — is not just exciting; it’s revolutionary. It’s akin to finding a Rosetta Stone in a sea of biological data, offering us a more integrated and nuanced understanding of complex systems.
The vanguard of Computer Vision: SSL’s transformative role
The realm of computer vision (CV) is undergoing a metamorphosis, thanks to SSL. The ICCV 2023 conference in Paris was a revelatory experience for me, showcasing the boundless potential of SSL in CV. It’s not just about big models and fine-tuning; it’s a paradigm shift in how we interact with visual data. Think of SSL combined with weak supervision as the new alchemists in the world of visual understanding.
Foundation models in SSL, these behemoths of pre-trained knowledge, are poised to redefine tasks from image classification to the more intricate challenges of visual reasoning. Their true magic lies in their chameleon-like ability to adapt to specific tasks, offering unparalleled versatility and efficiency.
SSL, the dawn of a new era
The journey of SSL is just beginning. Its evolution promises to be more than just incremental; it’s set to be revolutionary, reshaping how we approach, analyze, and derive meaning from data. The future of SSL, particularly in computer vision and the broader landscape of data science, is not just brimming with promise — it’s poised to be a transformative force.
Conclusion
As I reflect on this odyssey from the structured realms of PCA and ICA during my Ph.D. at the Curie Institute, to the explorative and innovative universe of Self-Supervised Learning (SSL), it feels like an enlightening journey, threading together various phases of my life. This transition symbolizes more than a shift in methodologies; it represents a personal evolution in understanding and harnessing the power of data.

Throughout this journey, several key learnings stand out. Firstly, the importance of foundational understanding — the principles of PCA and ICA have been crucial in grasping the nuances of SSL. Secondly, adaptability and continuous learning are not just beneficial but essential in the ever-evolving field of data science. Lastly, interdisciplinary collaboration, as I experienced in Paris, has been invaluable, teaching me that diverse perspectives often lead to groundbreaking innovations.
Looking ahead, I foresee SSL playing a pivotal role in areas beyond its current applications. The integration of SSL with emerging technologies like quantum computing or augmented reality could open new frontiers in data analysis and interpretation. Additionally, as artificial intelligence becomes increasingly autonomous, SSL may become central in developing more intuitive, self-improving AI systems.
For the data science industry, the implications are vast. SSL’s ability to leverage unlabeled data will become increasingly crucial as data volumes grow exponentially. This could lead to more efficient data processing and a deeper understanding of complex patterns, significantly benefiting sectors like healthcare, finance, and environmental science. Moreover, as SSL continues to evolve, it will likely drive a shift towards more sophisticated, nuanced data analysis methods across the industry.
In my current role, exploring different facets of data science, including my recent involvement in computer vision at Adevinta, I’ve seen firsthand the transformative impact of SSL. It’s a vivid reminder that our expertise is always evolving, built upon the foundations of our past experiences.
To my readers, I share this journey as an encouragement to embrace the vast and varied landscape of data science. Let your experiences guide and inspire you to explore new territories. The application of SSL across different fields, including my own explorations in computer vision, demonstrates the exciting potential of integrating past knowledge with cutting-edge innovations.
In the ever-changing world of data science, our greatest strength lies in our willingness to learn and adapt. The path of learning is endless, and I am eager to see where our collective curiosity and innovation will lead us next.
Recommended reading:
- https://arxiv.org/abs/2301.05712
- https://arxiv.org/pdf/2201.12680v2.pdf
- https://arxiv.org/abs/2305.13689
- https://arxiv.org/abs/2305.00729
- https://arxiv.org/abs/2111.06377
- https://arxiv.org/abs/2301.08243
- https://arxiv.org/abs/2304.07193
My related works
- PCA : DeDaL
- ICA: DeconICA & PhD Thesis
- Foundation models blog post
- about me