Deep Dive in PaddleOCR inference
Discover the complexities of using PaddleOCR as a Text in Image service and how the Cognition team overcame the challenges to improve user experience
Skills
- data science
- OCR
- deep learning
- computer vision
- machine learning
This article is a deep dive into part of our work as described in Article 1: Text in Image 2.0: improving OCR service with PaddleOCR.
We are Cognition, an Adevinta Computer Vision Machine Learning (ML) team working on solutions for our marketplaces. Adevinta is a global classifieds specialist with market-leading positions in key European markets that aims to find perfect matches between its users and the platforms’ goods. As a Global Team, our team, Cognition, provides image processing APIs to all of our marketplaces.
In the process of improving our OCR API for text extraction from images, we updated our existing Text in Image service to the PaddleOCR framework, which was the winner of our benchmarks. In order to test if this framework was the most suitable solution, we carried out a deeper analysis of their code base. This article shares the challenges we encountered and how we overcame them.
We believe our code version is easier to work with, given the use case of text extraction from images. The different steps and pre-processing and post-processing parts are clearly separated so they can be called independently, which should make further community extensions easier to add. It also makes putting into production easier, as the simplified, modular code combines well with the structure of inference.py for serving SageMaker endpoints. Our proposed code version does not alter predictions (compared to the 2.6 release) for images.
Understanding the PaddleOCR framework
PaddlePaddle (short for Parallel Distributed Deep Learning) is an open source deep learning platform developed by Baidu Research. It is written in C++ and Python, and is designed to be easy to use and efficient for large-scale machine learning tasks.
PaddlePaddle provides a range of tools and libraries for building and training deep learning models, including support for convolutional neural networks (CNNs), recurrent neural networks (RNNs) and long short-term memory (LSTM) networks.
PaddleOCR builds on PaddlePaddle, an unfamiliar framework that our team had not used before. To make things even more challenging, PaddleOCR is not just one algorithm, it includes a range of pre-trained models and tools for recognising text in images and documents, as well as for training custom OCR models.
PaddleOCR is divided into two main sections:
- PP-OCR, an OCR system used for text extraction from images
- PP-Structure, a document analysis system which aims to perform layout analysis and table recognition
PP-OCR exists in three different versions (V1, V2 and V3). In these different releases, major improvements were brought to the models’ architecture.
For our Text in Image service update, we focused on the most recent and most performant PP-OCRv3 release.
The PaddleOCRv3 models architecture
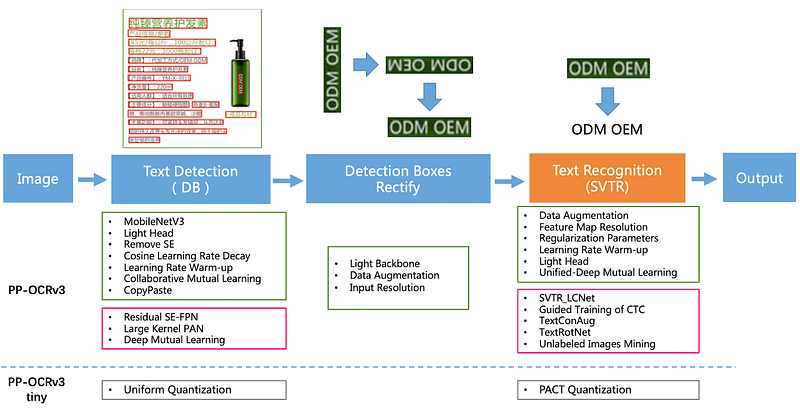
PP-OCRv3 is composed of three parts: detection, classification and recognition, all of which can be used independently. Each part has its own model trained with the PaddlePaddle framework. For those interested, model details can be found in this dedicated research article PP-OCRv3: More Attempts for the Improvement of Ultra Lightweight OCR System (Yanjun et al., 2022).
PP-OCRv3 text detection is made with the Differentiable Binarization algorithm (DB) trained using distillation strategy. The PP-OCRv3 recogniser is optimised based on the text recognition algorithm, Scene Text Recognition with a Single Visual Model (SVTR, Du et al. 2022).
PP-OCRv3 adopts the text recognition network SVTR_LCNet, and uses the guided training of Connectionist Temporal Classification (CTC, Zhiping et al., 2020) by the attention, data augmentation strategy, TextConAug, Unified Deep Mutual Learning and Unlabelled Images Mining (first introduced in PaddleOCRv2, Yanjun et al. 2021). The Text classifier is a simple binary classifier with classes 0 and 180°.
PaddleOCR inference in practice
While testing on our benchmarks, we used the PaddleOCR code for inference with default parameters and “latin” as a language (see their QuickStart page).
Reading the documentation and looking into the class parameters, we saw lots of model combinations to test and therefore more opportunities to potentially improve our score.
For instance, the documentation suggests there is a choice between “DB” and “EAST” algorithms for detection, but it’s only the main inference script where the algorithm has to be “DB” — the script of detection inference goes through a long list of algorithms. A similar situation occurs with text recognition where the pre-trained algorithm for Latin is “SVTR_LCNet”, but in theory, the accepted values are “‘CRNN’ and ‘SVTR_LCNet’ with the general documentation mentioning a plethora of models.
Pre-trained English models are available in “‘CRNN’ and ‘SVTR_LCNet’ architectures. However, to find the information, the user would need to look into the pretrained model config. If the user does not specify the “rec_algorithm”, the default value, “SVTR_LCNet”, would be used, even if it isn’t correct. This doesn’t actually make any difference to the inference code as none of the “if” applies to ‘CRNN’ or ‘SVTR_LCNet’.
In order to test a different architecture, we would need to train it ourselves and chain dedicated scripts.
Clarifying PaddleOCR inference
From digging into the code, we discovered several complexities, unnecessary for our use case. Firstly, the code seemed to grow organically, where the inference version is a limited choice entry to the multi-option code. This leaves us with numerous “factory patterns” and “if .. elses”, where the user has no choice at all. The English documentation was confusing and referenced different usage cases. We struggled to follow the logic as it neither explained parameters, nor clearly defined the limitations of the inference code.
Despite these complexities, we managed to clarify the general way of working, calling the PaddleOCR.ocr() method from the ‘master’ file, paddleocr.py.
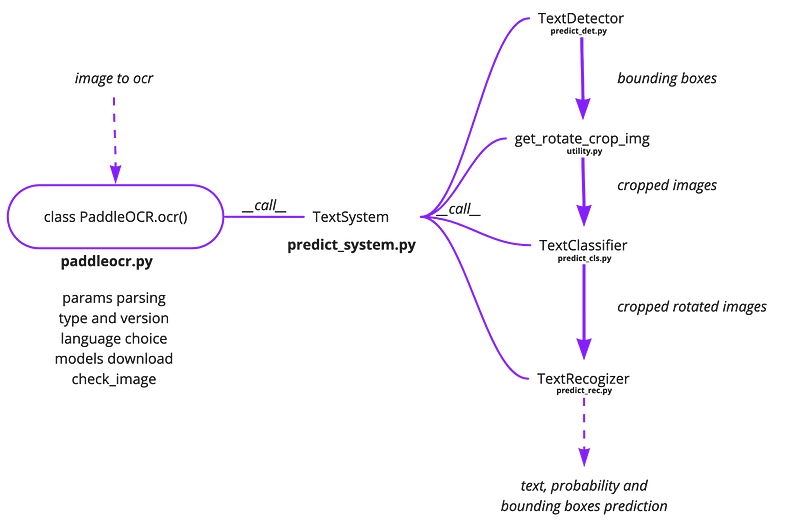
The input image and parameters are entered into the PaddleOCR.ocr() method which calls TextSystem class in order: TextDetector, TextClassifier and TextRecogniser, with a selection of helper functions, including one that formats the outputs of TextDetector into a list of cropped images being input to TextClassifier and TextRecogniser.
The PaddleOCR.ocr() method is parsing params, including the language, version, type of OCR (or structure), downloads inference models and imports actual image (with check_image).
If we want our image to go through a full OCR process, the TextSystem class will sequentially call classes responsible for detection, classification and recognition.
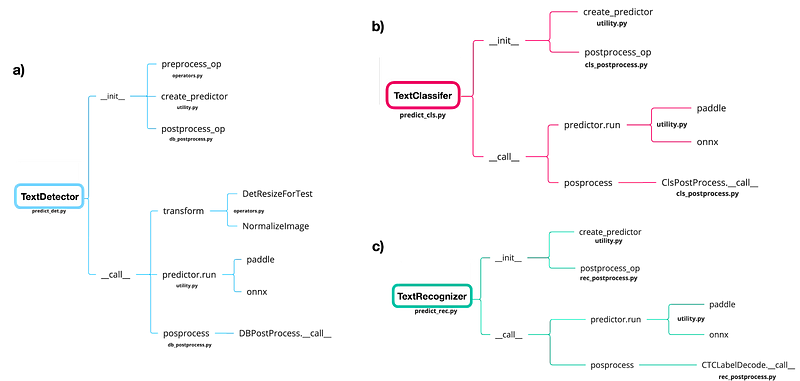
Each of the main classes has an __init__ method that initialises pre- & post- processing classes and loads the model (create_predictor), and __call__ method that executes (pre- &) post-processing on the image and performs the model inference for the input image(s).
Most of the scripts used for inference can be found under ‘tools/infer/’. The pre-processing scripts are under “ppocr/data/imaug/operators.py”. The post-processing classes are under ‘ppocr/postprocess/’.
This schema enables us to reduce the essential inference code to just a couple of files and better understand exactly how the code works. To make it easier to maintain, we decided to reformat the code, keeping only the essential parts for our use case.
PaddleOCR inference code caveats and fixes
Let’s walk you through the PaddleOCR features we didn’t like and suggestions on how they could be improved.
Spaghetti code
Overall, most of the code is in object oriented programming style where classes are not modular and most things happen in very long __init__ and __call__ methods. We have noticed (fig. 2 and fig. 3) that generally, three parts can be extracted: pre-processing, inference and post-processing. We have removed ‘create_operators’ and ‘build_post_process’ intermediate functions and called directly the class performing the task such as “DBPostprocess” and “NormalizeImage”. To make things more straightforward, we transformed them into simple functions, performing what their __call__ method was doing before. This leaves us with more modular code and direct logic that fits our needs.
Parameter parsing
We found it problematic that the inference class requires 105 parameters, of which more than 70 were ignored.

English documentation lists the parameters and gives a succinct definition of them. In the code, they are defined in at least three different places: paddleocr.py, utility.py and different utility.py.
However while executing the code, we found that only 20 parameters were useful in our refactored code:
When rewriting the code, we cleaned the parameter list, leaving only the relevant parameters.
Parameter impact on prediction
Some of the parameter definitions and effect they would have when changed from default, were not clear to us. We built a Streamlit app to visualise the changes in params on the predictions. For instance, “unclip ratio” would impact the size of the box, and “threshold” would detect two bounding boxes instead of one. We advise you to play with your own data and model to see how different parameters affect the detection. Overall, we were not able to see a major improvement from changing defaults.

Language choice
Normally in our role, we work with “‘PP-OCRv3”, the most recent version of the framework. As we are dealing with European languages, we would choose “fr”, “en”, “es” as the “lang” param, thinking that this means different models are being called. However, while looking into the paddleocr.py, we saw how the languages are interpreted:
The first definition serves to define the recognition model name/path. But if we typed “fr” or “es”, it becomes lang = “latin”, yet “en” remains “en”. Then another simplification happens for the detection model.
if lang in [“en”, “latin”]:
det_lang = “en”
We are left with an English detection model and a Latin recognition model for any European language written with Latin characters except English, which has its own recognition model.
Downloading models
Based on the language parameter and framework version, the first time we call the PaddleOCR class with those parameters, the model will be downloaded from the url encoded in paddleocr.py.
Firstly, this could cause some issues when running the code in secure or offline environments.
Secondly, we found inconsistencies between the model urls in the paddleocr.py and the models provided in the dedicated documentation page. For instance, “en_PP-OCRv3_det_slim” is not an option when models are downloaded by the paddleocr.py script. In order to use some of the models from Model Zoo, a database of pre-trained models and code, you would need to download the model and provide the path to it manually.
In order to remove this ambiguity and use the specific model we needed, we decided to pre-download the chosen model, then provide the path directly. In the original code, it is possible to provide det_model_dir, cls_model_dir and rec_model_dir. The language param will then be ignored and any pre-trained model with the accepted backbones can be used. After this process, we removed the model download functionality from our code.
Using ONNX models
PaddleOCR provides a handy way to export models to the ONNX framework that can serve or integrate in different pipelines. We exported the pre-trained models using PaddleOCR instructions. In the PaddleOCR class, there is a parameter “use_onnx”. If one sets “use_onnx” and provides a direct path to the ONNX models to PaddleOCR(), the model would use the ONNX model for prediction. However, there is a small bug that occurs while running ONNX with GPUs, described further in this issue.
We applied the modification suggested and tested the code with ONNX models, obtaining satisfactory results on both CPU and GPU (even though we noticed small numerical differences between the Paddle and ONNX model versions).
Documentation
If you look at the documentation pages, you will find a lot of resources in both English and Chinese. However, when looking at Issues, you will find most of them are in Chinese, Japanese or Korean. The same applies to blog posts and community resources online. We also found that some documentation is only partially translated to English and the Chinese version contains much more detail.
We did not find a solution for this. We made sure to always check both the English and Chinese documentation (translated to English by an automatic translator) to ensure that we have all the possible information.
Tests & pylint & typing
In general, as the original code is not modular, it was not tested according to the standards of our team. Once we cleaned and simplified the code, we worked on linting and variable typing. Our next step will be to write meaningful unit tests to secure the code base.
Summary
PaddleOCR is a powerful and optimised library for the extraction of text from images. However, we found that the code doesn’t fit the standards of our team as it is too complex to maintain and understand. In this article, we pointed out some of the pain points for us that other PaddleOCR users may experience when working with this framework. The fixes we proposed made our lives easier and the code more transparent for any team member and the wider community, without compromising the speed or the original model accuracy.