Text in Image 2.0 - improving OCR service with PaddleOCR
Read how the Cognition team improved the Text in Image service across Adevinta marketplaces using PaddleOCR
Skills
- data science
- OCR
- deep learning
- computer vision
- machine learning
- API
Understanding OCR: What is Optical Character Recognition?
Optical Character Recognition (OCR) is a popular topic for both industry and personal use. In this article, we share how we tested and used an existing open source library, PaddleOCR, to extract text from an image. This read is for anyone who would like to find out more about OCR, the needs of our customers at Adevinta, and the challenges we face in attending to them. You’ll find out how we upgraded an existing service, benchmarked different solutions and delivered the selected one to satisfy our customers.
Key OCR applications: How OCR transforms business and daily operations
OCR stands for “Optical Character Recognition” and is a technology that allows computers to recognise and extract text from images and scanned documents. OCR software uses optical recognition algorithms to interpret the text in images and convert it into machine-readable text that can be edited, searched and stored electronically.
There are numerous use-cases where OCR can be used:
- Digitising paper documents: to convert scanned images of text into digital text. This is useful for organisations that want to reduce their reliance on paper and improve their document management processes.
- Extracting data from images: eg from documents such as invoices, receipts and forms. This can be useful for automating data entry tasks and reducing the need for manual data entry.
- Translating documents: to extract text from images of documents written in foreign languages and translate them into a different language.
- Archiving: to create digital copies of important documents that need to be preserved for long periods of time.
- Improving accessibility: to make scanned documents more accessible to people with disabilities by converting the text into a format that can be read by assistive technologies such as screen readers.
- Searching documents: to make scanned documents searchable, allowing users to easily find specific information within a large collection of documents.
The Adevinta context: Why OCR matters in global marketplace
Within Adevinta, a global classifieds specialist with market-leading positions in key European markets, there is space for all of the cited use cases. However, for this article, we focus specifically on “extracting data from images.”
Applying deep learning to images is the main expertise of our team, Cognition. We are Data Scientists and Machine Learning (ML) Engineers that work together to develop image-based ML solutions at scale, helping Adevinta’s marketplaces build better products and experiences for their customers. Adevinta’s mission is to connect buyers and sellers, enabling people to find jobs, homes, cars, consumer goods and more. By making an accessible ML API with features tailored to our different marketplaces’ needs, Adevinta’s marketplaces are empowered with ML tools at a reasonable cost.
Text Extraction in Images: Why It’s Crucial for Adevinta’s Services
Text extraction from images enables us to:
- Detect unwanted content in ads (e.g., insults, hidden messages).
- Better understand image content to improve search capabilities.
- Support more efficient searches using visible text on items.
With over 100 million requests per month and growing, our existing Text in Image service was ripe for enhancement. We aimed to improve accuracy and performance, leading to the development of Text in Image 2.0.
Why we chose PaddleOCR: Benchmarking the best OCR solution
The existing service was based on Fast Oriented Text Spotting with a Unified Network (Yan et al., 2018). Despite being state of the art in 2018, the algorithm achieved 0.4 accuracy on our internal benchmark of 200 marketplace images. Nevertheless, accuracy was not the sole criteria of choice for the Text in Image 2.0, so we compiled a list of edge cases where our partner marketplaces require high-performing algorithms.
After reviewing different open source OCR frameworks (including MMOCR, EASY OCR, PaddleOCR and HiveOCR) and different combinations of proposed models on our internal benchmark and on the edge cases, a indisputable winner was PaddleOCR with an average accuracy of 0.8 and an acceptable performance on our edge cases. This result competes with the paid Google Cloud Vision OCR API on the best accuracy we measured.
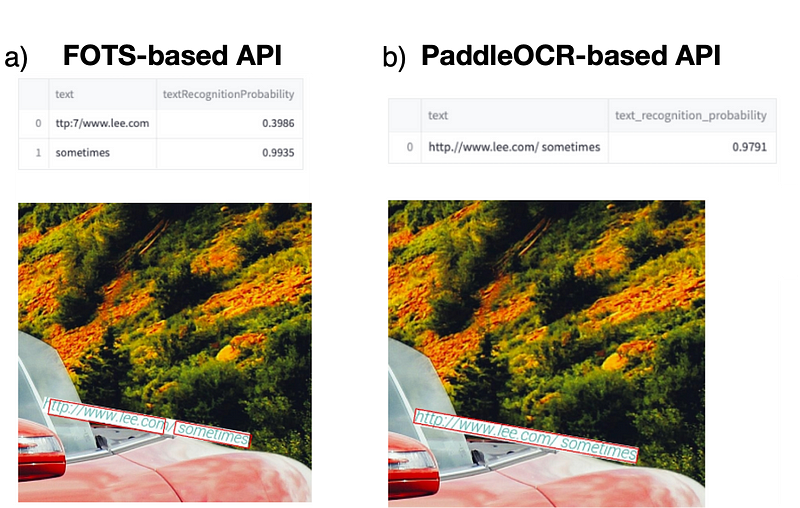
How We Validated PaddleOCR: Building a Comprehensive Benchmark
In order to construct our independent benchmark and validate the choice of PaddleOCR at scale, we built a “Text in Image generator” that uses open source images from Unsplash and Pikwizard and adds randomly generated text on top of them. The created tool is highly customisable in order to simulate a wide variety of cases that combine factors such as font type, rotation, text length, background type, image resolution etc. Using a simulated benchmark of 20k images with a distribution of cases matching business needs, we obtained an improvement factor of x1.4.

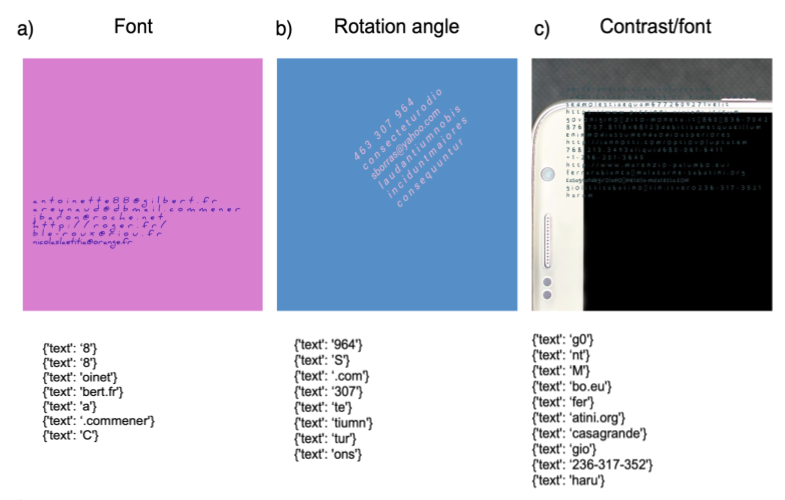
Challenges with PaddleOCR: Identifying and mitigating issues
We identified several cases where PaddleOCR fails. This is mostly when there are different angles of rotated text, some alternative fonts and differing colour/contrast. We also observed that in some cases, the correct words are detected but the spaces between them are not placed correctly. This may or may not be an issue depending on the way the extracted text is used further.
Deep Dive: How We Optimized PaddleOCR for Production
In order to evaluate the potential for improvement and mitigation of these errors, in addition to defining the serving strategy, we had to deep dive into the PaddleOCR framework.
PaddleOCR builds on PaddlePaddle. Our team had no previous experience with this and it’s less popular in our community than other frameworks such as Tensorflow, Keras or Pytorch.
From a technical point of view, PaddleOCR is composed of three distinct models:
- Detection, for detecting a bounding box where possible text is
- Classification, rotating the text 180° if necessary
- Recognition, translating the detected image frame to raw text
Pre-trained models in different languages are provided by authors.
Refactoring PaddleOCR: Creating a Clean, Production-Ready Codebase
Whilst exploring the code base of PaddleOCR for inference, we were faced with convoluted code, which was difficult to read and understand. As we wanted to use the PaddleOCR solution in production, we decided to refactor the code, keeping in mind to preserve the performance and the speed of the original code. You can read about the details of that process and the PaddleOCR model in the complementary article of this series. After refactoring the code, we had created a clean and readable code base.
We believe our code version is easier to work with, given the use case of text extraction from images, and are working on making the code available open source. The different steps and pre-processing and post-processing parts are clearly separated, so they can be called independently, which should make further community extensions easier to add. It also makes putting into production easier, as the simplified, modular code combines well with the structure of inference.py for serving SageMaker endpoints. Our proposed code version does not alter predictions (compared to the 2.6 release) for images.
Deploying Text in Image 2.0: Achieving Superior Performance with PaddleOCR
Using the refactored code, we made the model available as an API. To help our customers’ transition, we maintained the same API contract used in the previous service.
Serving PaddleOCR can be done in multiple ways. The straightforward approach is calling its own Python API (provided by the PaddleOCR package) from within a well-known framework. We selected Multi Model Server, Flask and FastAPI to conduct our benchmark. All our proposed solutions are served by AWS SageMaker Endpoint, building our own container (BYOC) from the same Docker base image.
MultiModel Server uses its own JAVA ModelServer, while for Flask and FastAPI, we use nginx+gunicorn (combined with uvicorn workers for the ASGI FastAPI). The frontend for our customers is served by an API Gateway, which is out of the scope of this article.
Benchmarking Deployment Options: Multi-Model Server, Flask, and FastAPI
For the performance testing, we recreated a number of requests with a controlled amount of text and different image sizes, mimicking the expected distribution from our customers. We used Locust as the testing framework, and stimulated heavy bursts in the waiting time as a stress test.
With the data gathered from the performance tests, we were able to define our infrastructure (type of instance and autoscaling policy) in relation to the Service Level Agreement (SLA) terms, while balancing the risk of a sudden shift from the observed distribution (the service is sensitive to the amount of text per image).
Currently, we deal with 330 million requests per month, and we have estimated that next year, more Adevinta marketplaces will onboard a Text in Image service, resulting in a 400% growth.
Results and impact: Transforming Text in Image service with PaddleOCR
The new API resulted in an improved latency 7.5x compared to the FOTS-based solution, while providing a 7% cost reduction in serving. Also, since the new API being 12x cheaper than a typical external solution, such as GCP OCR, we received positive feedback from our users about both the speed and the accuracy of the Text in Image 2.0.
Key Takeaways: Enhancing OCR with PaddleOCR
As a computer vision team working for an international company serving millions of people every day, we aimed to improve our OCR API for text extraction from classified ads. After testing numerous frameworks, we built an image simulator in order to find the algorithm matching the needs of our users. The selected framework, PaddleOCR, went through our internal review and revamp. (There were challenges along the way and you can read more about them in Article 2: Deep Dive in PaddleOCR inference). Now, we’re pleased to say we’re providing a more accurate, faster and cheaper API using the PaddleOCR framework.